
CES 2026專題|CES 2026 不是新品發表,而是黃仁勳為未來十年 AI 公開定錨的時刻
作者:智璞產業趨勢研究所執行副總 林偉智
CES(Consumer Electronics Show)是由美國消費者技術協會舉辦,全球最大規模的消費性電子展,首先登入大眾目光的,當然就是nVIDIA執行長黃仁勳的Keynote。許多人仍以「新品規格」、「效能提升幅度」與「短期需求訊號」解讀 CES 2026黃仁勳的 keynote,我認為黃實際上傳遞的是一個更高層次、也更長時間尺度的訊息:nVIDIA 正在嘗試為未來十年的 AI 發展,公開錨定其技術路徑、產業邊界與資本支出的重心所在。這並非一場產品發表會,而是一場
從模型到平台:Scaling Law 的位置正在改變
黃仁勳在演講中清楚指出一個現實限制:模型參數規模與推論 token 數量仍在高速成長,但可用電晶體與能效改善速度已無法同步跟上。這等同於承認,傳統以製程與模型規模為核心的 scaling 路徑,已接近邊際效益遞減的區間。Vera Rubin 平台的真正意義,並不在於「效能是前一代的幾倍」,而在於它代表 nVIDIA 對 scaling law 的重新定義,從模型層,轉移到系統層與平台層。這也是為何 Vera Rubin 並非單一晶片,而是一次性重新設計 CPU、GPU、NVLink Switch、NIC、資料中心交換器與 DPU 的「極端共同設計」。在這個架構中,效能的提升不再來自單點突破,而是來自於以下幾件事的同步成立:
- 精度可動態調整的運算單元(如 NVFP4)
- 訓練、推論與 test-time reasoning 各自最佳化
- 記憶體、網路與儲存不再成為 scaling 的隱性天花板
- 能源與電力調度被視為系統設計的一部分,而非外部條件
這不是延續舊有 scaling law,而是試圖讓 「有效運算量」持續成長,即便單一元件的進步速度已放緩。

source: nVIDIA
其中一個重要的訊號是,nVIDIA 對推論記憶體架構的重新定義。透過新的 Context Memory 與 DPU 管理架構,讓KV cache 不再只是暫存資料,而被提升為可被調度、共享與保護的系統級資產。這個轉變,讓記憶體與儲存不再只是算力的附屬成本,而是直接影響推論效率、服務品質與資本報酬率的關鍵變數。換句話說,他不是在優化KV cache這個必要但麻煩的暫存資料(向量),而是在重新定義 AI 推論時「什麼才是真正的資產」。對 nVIDIA 而言,這不僅提升了 GPU 的實際變現能力,也讓其軟體與平台層對整個 AI 基礎設施的掌控進一步加深。從這個角度看,Vera Rubin 所代表的,並非單一世代產品,而是一套試圖將 算力、記憶體、網路與軟體統合為「可長期營運的平台資產」 的系統設計。我覺得,算是變相回應之前外界對伺服器折舊的疑慮。
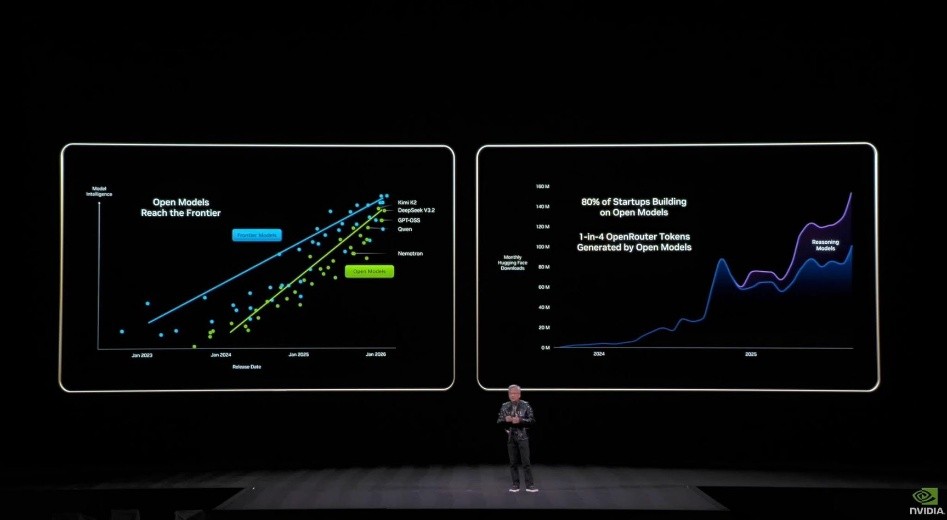
Open Models Reach the Frontier:開放模型不是理想,而是結構需求
如果說 Vera Rubin 是對算力供給面的定錨,那麼 Physical AI 則是對需求結構的定錨。黃仁勳花了不少篇幅說明 AI不應再被理解為僅存在於資料中心與螢幕中的工具,像是生成簡報或找到你愛口味的滷肉飯店家,而是即將成為「理解、推理並影響真實世界」的決策系統。也就是Physical AI。
source: nVIDIA
黃提到,目前開放模型[Open Models]的能力曲線已逼近前沿模型,而使用開放模型的新創與企業,正快速成為主流。因此他認為重點並不在於哪一個模型最強,而在於開放生態的擴散速度與覆蓋廣度。nVIDIA 把「模型」變成可部署的單位,而不是一項研究成果得以讓使用者或企業更容易使用,同時將「硬體 × 軟體」變成類似 App Store 的關係。

source: nVIDIA
自動駕駛、機器人、工業設備與智慧工廠,並不是零散的應用場景,而是同一個趨勢不同投射面。順著黃的邏輯,我認為Alpamayo 推出在自駕平台上的象徵意義,不在於 nVIDIA 是否能在自駕市場擊敗既有玩家,而在於它清楚揭示了 nVIDIA 的定位選擇,是成為 Physical AI 的開放平台,而非終端品牌。這種策略,使其潛在市場不再受限於單一產業或單一商業模式,而是直接連結到全球汽車、製造、物流與工業設備的長期資本支出循環。一旦 AI 開始實質參與「車輛如何行駛」、「產線如何配置」、「設備如何自我優化」,算力需求將不再集中於少數的Hyperscaler資料中心,而是呈現高度分散、長期且跨景氣循環的特性。當然,馬斯克對於nVIDIA推出自駕平台的回應也令人玩味,他認為FSD後期遇到的許多問題才是考驗的開始。
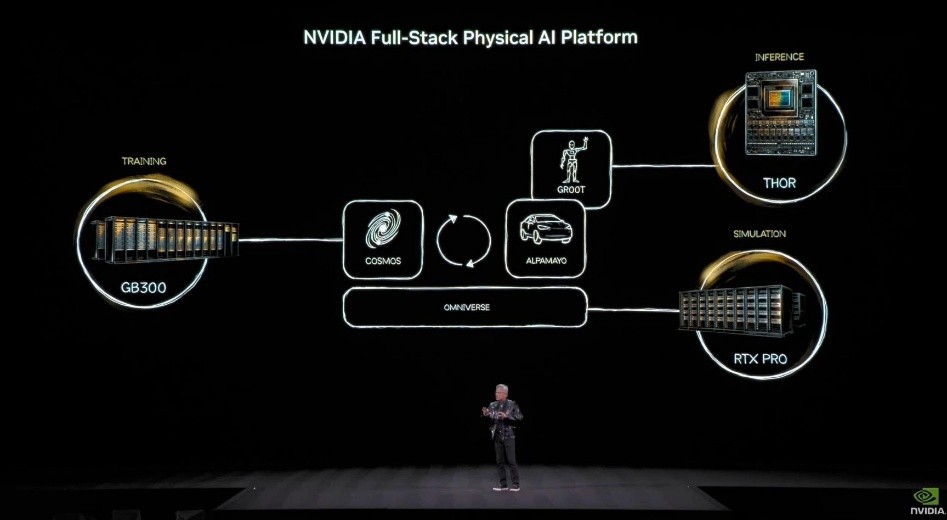
在資料中心層級,訓練、推論或是模擬它們可以共享同一套可程式化GPU架構,但在 Physical AI 架構中,推論最終必須往邊緣與實體裝置移動,形成相互不可被完全取代的節點。黃延續此概念把Physical AI 平台依據部屬的場景拆解成訓練、模擬與推論。並明確視為三種不可互相取代的領域,同時存在、彼此協作。
- 訓練:資料中心等級(GB300)
- 模擬:生成合成資料、建構世界模型(RTX Pro)
- 推論:部署於車輛、機器人與設備端(Thor)
source: nVIDIA
在這三個領域中,Physical AI 的學習不是一次性訓練,而是「模擬->部署->回饋」的持續循環。也正是在這個循環中,AI scaling的資料來源被重新打開。AI 在模擬中學習,在現實中驗證,再回到模擬中修正,這個過程本身,就構成了新的 scaling 來源。
我覺得,這場 keynote 與其說是在展示目前nVIDIA既有優勢,不如說是在反映了黃仁勳心中抱持滿滿的危機感。但這不是對短期競爭的焦慮,而是對「AI 成長路徑可能被他人重新定義」的警覺。這個Keynote並非nVIDIA對未來的單向預測,而是一個高度主動、甚至帶著強烈危機意識的戰略行動。當模型規模持續放大、競爭者快速追趕、而摩爾定律已無法單獨支撐成長時,若不重新定義 AI 的成長路徑,領先地位終將被消耗在同質化競爭中。因此,我認為這場keynote 的核心,不是宣告 nVIDIA 已經贏了競爭或未來發展堪慮,而是試圖把 AI 的競爭焦點,從模型參數與單點算力,推進到系統工程、平台整合與現實世界的運作邏輯。平台規模、Physical AI、scaling、以及訓練、模擬與邊緣推論的閉環設計,都是「下一個十年仍能持續放大優勢」的戰略佈局。當市場仍以「GPU 出貨循環」理解 AI 產業時,黃仁勳試圖把時間軸拉到十年,並清楚劃出邊界。未來真正的競爭,不在於誰的模型最大,而在於誰能在高度競爭與不確定性中,讓 AI 成為現實世界中可長期運作、可被信任、且可持續擴張的決策引擎。
台廠的商機
在討論完戰略方向之後,Vera Rubin作為下一代AI Server 產品,想當然要有一定的升級來面對token數量平均增長5倍/年的情況。在訓練模型上,其效能比前一代Blackwell晶片提升3.5倍,在執行AI軟體時則快 5 倍。此外,新的中央處理器(CPU)擁有88個核心,效能是原先的兩倍。不僅如此, Vera Rubin AI Server,採用六顆晶片架構,CPU與GPU可雙向、低延遲共享資料系統可提供100 petaflops的AI運算能力,是前一代的五倍。在資料互聯方面,導入第六代NVLink交換器,可連接18個運算節點,支援最多72顆Rubin GPU同步運作,資料傳輸量超過全球網際網路總和。配合全球首款512通道、200Gb共封裝光學乙太網路交換器Spectrum-X,能將數千機櫃組成完整的AI工廠。這裡也是過去所說CPO導入的時間點。而整體AI Server系統層級上,72顆GPU組成的Vera Rubin NVL72機架,總記憶體頻寬可達1.6PB/s,較Blackwell平台提升近兩倍。
沒有意外的,根據過去宣布的新技術導入時程,這一代在電力上力推AI伺服器電源管理IC升級,800V的高壓直流(HVDC)元件將成市場趨勢,電源廠商的台達電、光寶科以及相關化合物半導體廠有機會直接搶攻商機;同時會導入台積電的晶背供電(BSPD)製程,讓先關晶圓薄化設備廠中砂、昇陽半以及PVD設備天虹等獲得相關商機。
還有許多升級所帶來的商機,像是冷卻設備、矽光等都令人期待,其中讓我印象深刻的是延續上面提到的nVIDIA 對推論記憶體架構的重新定義所改變的硬體。nVIDIA在加入Context Memory Storage Platform並推動DPU SSD Rack。換句話說,把原本屬於資料中心後段的資料處存的SSD,拉進 AI 推論的即時路徑,讓 SSD 從「容量設備」升級成「推論效能的一部分」。成為支撐長上下文、多回合代理與高並發推論的關鍵資源。這將催生一個以 DPU 為核心、以高效能企業級 SSD 為主體的全新儲存市場,其價值不在於容量本身,而在於對 AI 工廠吞吐量與投資報酬率的放大效應。Sandisk 的股價在發布的前後,表現非常強勁,台灣相關控制器與模組廠未來也是很有機會受惠此相關商機。








