
January CES _2026 Feature|CES 2026 is not about new product announcements, it's about Jen-Hsun Huang setting the anchor for the next decade of AI openness.
Author: Mr. Lin Weizhi, Executive Vice President, Ji-Pu Industrial Trend Research Institute
CES (Consumer Electronics Show) is the world's largest consumer electronics show organized by the Consumer Technology Association, and the first thing that came to the public's attention was of course the keynote by nVIDIA CEO Jen-Hsun Huang. Many people still interpret CES 2026 as a "new product specification", "performance improvement", and "short-term demand signal". I think what Huang actually conveyed in his keynote was a higher-level, longer-term message: nVIDIA is trying to publicly anchor its technology path, industry boundaries, and capital spending priorities for AI development in the next decade. This is not a product launch event, but rather a
From Models to Platforms: The Place of Scaling Law is Changing
In his talk, Jen-Hsun Huang clearly pointed out a practical limitation: the model parameter scale and the number of inferred tokens are still growing at a fast pace, but the available transistors and energy efficiency are not improving at the same pace. This is tantamount to admitting that the traditional scaling path, which is centered on process and model size, is approaching the point of diminishing margins, and that the true significance of the Vera Rubin platform is not that it "doubles the performance of its predecessor," but rather that it represents a redefinition of the scaling law, moving from the model layer to the system and platform layers. This is why Vera Rubin is not a single chip, but an "extreme co-design" that redesigns the CPU, GPU, NVLink Switch, NIC, Data Center Switch and DPU all at once. In this architecture, performance improvements no longer come from a single breakthrough, but from the synchronization of several things:
- Operational units with dynamically adjustable precision (e.g. NVFP4)
- Optimization of training, inference, and test-time reasoning
- Memory, networking and storage are no longer hidden ceilings for scaling.
- Energy and power dispatch are seen as part of the system design, not as external conditions
This is not a continuation of the old scaling law, but an attempt to keep the "effective amount of computation" growing, even as the rate of progress in a single component slows.

source: nVIDIA
One of the key signals is nVIDIA's redefinition of the inferred memory architecture. With the new Context Memory and DPU management architecture, the KV cache is no longer just a temporary store of data, but a system-level asset that can be scheduled, shared and protected. With this change, memory and storage are no longer just ancillary costs of computing power, but key variables that directly affect inferential efficiency, service quality, and return on capital. In other words, instead of optimizing the KV cache, which is a necessary but troublesome temporary data (vector), he is redefining "what is the real asset" when it comes to AI inference. For nVIDIA, this not only improves the real-world realism of GPUs, but also gives its software and platform layers greater control over the entire AI infrastructure. From this perspective, what Vera Rubin represents is not a single-generation product, but a system design that attempts to unify computing power, memory, networking, and software into a "platform asset that can be operated over the long term. In my opinion, this is a response to the previous concerns about server depreciation.
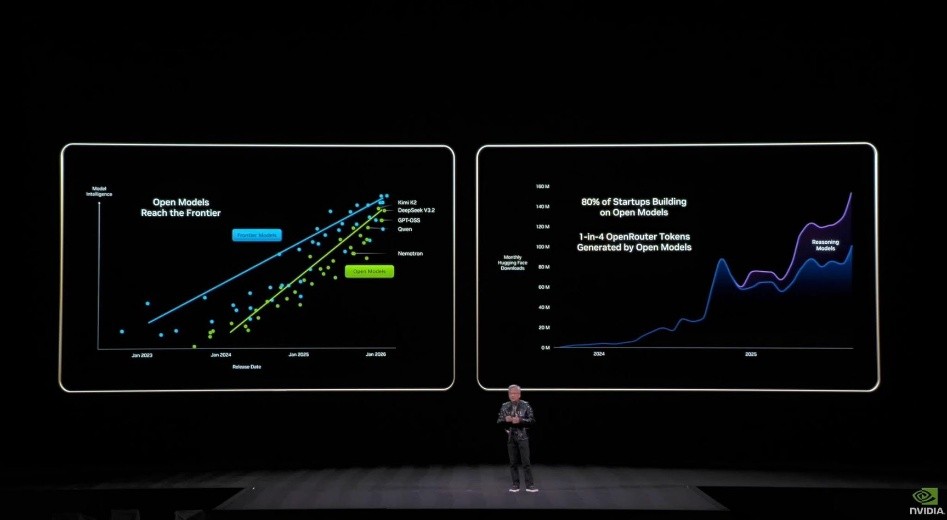
Open Models Reach the Frontier: Open modeling is not an ideal, but a structural requirement
If Vera Rubin is the anchor for the supply side of computing power, then Physical AI is the anchor for the demand structure. Jen-Hsun Huang spent a lot of time explaining that AI should no longer be understood as a tool that exists only in data centers and screens, such as generating presentations or finding a restaurant that serves the marinated pork rice that you like, but is about to become a decision-making system that "understands, reasons, and affects the real world". Physical AI.
source: nVIDIA
Huang mentioned that the capability curve of Open Models is now approaching that of cutting-edge models, and that start-ups and enterprises using Open Models are rapidly becoming mainstream. Therefore, he believes that the focus is not on which model is the strongest, but on the speed of spreading and coverage of the open ecology. nVIDIA has turned "models" into deployable units rather than a research result to make it easier for users or enterprises to use them, and has turned "hardware × software" into a relationship similar to an App Store.

source: nVIDIA
Autonomous driving, robotics, industrial equipment and smart factories are not fragmented application scenarios, but rather different projections of the same trend. Following Huang's logic, I think the symbolic significance of Alpamayo's launch on the self-driving platform is not whether nVIDIA can beat existing players in the self-driving market, but rather that it clearly reveals nVIDIA's choice of positioning itself as an open platform for Physical AI, rather than a terminal brand. With this strategy, the potential market is no longer limited to a single industry or business model, but is directly connected to the long-term capital expenditure cycle of automotive, manufacturing, logistics and industrial equipment worldwide. Once AI begins to participate in "how vehicles run," "how production lines are configured," and "how equipment optimizes itself," the demand for arithmetic power will no longer be concentrated in a handful of Hyperscaler data centers, but will instead be highly decentralized, long-term, and cross-cyclical in nature. Of course, Mask's response to nVIDIA's launch of the self-driving platform is also intriguing, as he believes that the many problems encountered in the latter stages of FSD are the beginning of the test.
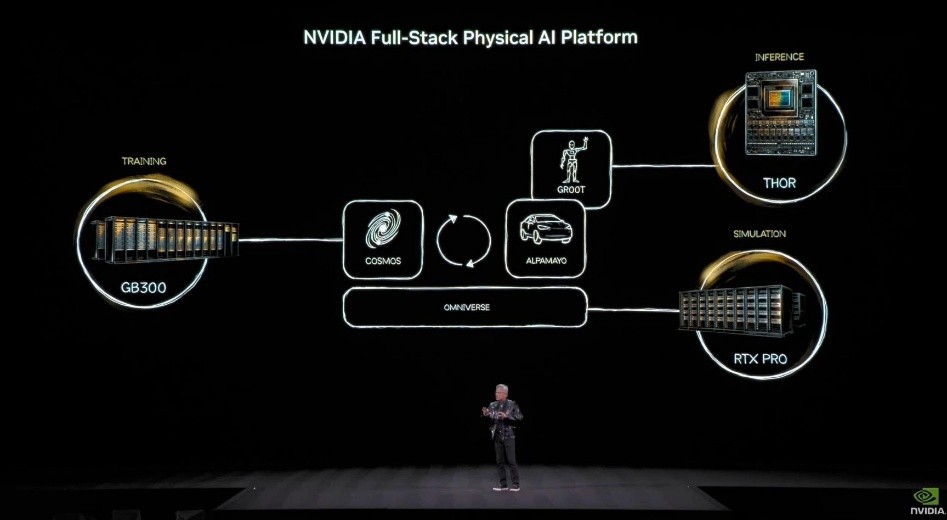
At the data center level, training, inference, and simulation can share the same programmable GPU architecture, but in a Physical AI architecture, inference must ultimately move to the edges and to physical devices, forming nodes that are not completely replaceable with each other. Huang continues this concept by breaking down the Physical AI platform into the following scenarios based on its componentsTraining,simulationandinferenceIt is also clear that the three areas are irreplaceable and co-exist and collaborate with each other. The three areas are clearly seen as irreplaceable, co-existing and collaborating with each other.
- Training: Data Center Level (GB300)
- Simulation: generating synthetic data, modeling the world (RTX Pro)
- Theory: Deployment in Vehicles, Robots and Devices (Thor)
source: nVIDIA
In these three areas, the learning of Physical AI is not a one-time training, but a continuous cycle of "simulation->deployment->feedback", and it is in this cycle that the data source of AI scaling is reopened. It is also in this cycle that the data source for AI scaling is reopened, and the process of AI learning in simulation, verifying in reality, and then returning to simulation to make corrections, constitutes a new source of scaling.
I think this keynote is not so much a demonstration of nVIDIA's existing strengths as a reflection of the sense of crisis that Jen-Hsun Huang holds in his heart. However, this is not a short-term competition anxiety, but an alert to the "AI growth path may be redefined by others". This Keynote is not a one-way prediction of the future by nVIDIA, but a highly proactive strategic action, even with a strong sense of crisis. When the model scale continues to increase, competitors are catching up fast, and Moore's Law can no longer support growth on its own, if we don't redefine the growth path of AI, our leading position will eventually be consumed by homogenized competition. Therefore, I think the core of this keynote is not to declare that nVIDIA has won the competition or to worry about the future development, but to try to push the focus of AI competition from model parameters and single-point arithmetic to system engineering, platform integration, and the logic of operation in the real world. Platform scale, physical AI, scaling, and the closed-loop design of training, simulation, and marginal inference are all strategic layouts that will "continue to amplify our advantage in the next decade. While the market still understands the AI industry in terms of the "GPU shipment cycle," Jen-Hsun Huang tries to stretch the timeline to ten years and draw a clear boundary. The real competition in the future is not about who has the biggest model, but who can make AI become a decision engine in the real world that can be operated in the long run, be trusted, and continue to expand in the midst of high competition and uncertainty.
Business Opportunities for Taiwan
After discussing the strategic direction, Vera Rubin, as the next-generation AI Server product, of course, needs to be upgraded to face the average 5x/year increase in the number of tokens. In terms of training models, it delivers 3.5x performance improvement over the previous generation Blackwell chip and 5x faster in running AI software. In addition, the new central processing unit (CPU) has 88 cores and is twice as powerful. Additionally, the Vera Rubin AI Server, with its six-chip architecture and bi-directional, low-latency data sharing between the CPU and GPU, delivers 100 petaflops of AI computing power, five times more than its predecessor. In terms of data interconnection, the sixth-generation NVLink switch is introduced, which can connect 18 computing nodes and support up to 72 Rubin GPUs in synchronized operation, with a data transmission capacity exceeding the total of the global Internet. Together with Spectrum-X, the world's first 512-channel, 200Gb co-packaged optical Ethernet switch, thousands of cabinets can be organized into a complete AI factory. This is also the point at which CPO was introduced. At the overall AI Server system level, the Vera Rubin NVL72 rack, which consists of 72 GPUs, has a total memory bandwidth of up to 1.6PB/s, which is nearly twice as much as the Blackwell platform.
Unsurprisingly, based on past announcements of new technology introduction schedules, this generation is pushing AI server power management IC upgrades in terms of power, and 800V high-voltage direct current (HVDC) components will become a market trend.Delta Power, a power supply manufacturer,Lite-On and related compound semiconductor companies have the opportunity to directly seize the business opportunity.This will also introduce TSMC's Back Side Power Delivery (BSPD) process, which will allow the first to turn off the power.Business opportunities for wafer thinning equipment makers Nakasago and Sunrise, and PVD equipment Tianhong.The
There are also a lot of business opportunities brought by upgrades, such as cooling equipment, silicon light, etc., which are expected, and the one that impresses me is the continuation of the hardware that has been changed by nVIDIA's redefinition of the inferred memory architecture mentioned above. nVIDIA has joined the Context Memory Storage Platform and promoted the DPU SSD Rack. In other words, it has brought the SSDs that were originally part of the data center's back-end data storage into the real-time path of AI inferences, making SSDs from "capacity devices" to "part of inferred performance". In other words, the SSDs that originally belonged to the back-end of the data center for data storage have been pulled into the real-time path of AI inference, upgrading SSDs from a "capacity device" to a "part of the inference performance". SSDs will become a key resource for supporting long context, multi-round agents, and highly concurrent inferences. This will create a new storage market centered around DPUs and high-performance enterprise SSDs, where the value is not in the capacity itself, but in the amplification of throughput and ROI for AI factories. Sandisk's stock price was very strong before and after the announcement.Taiwan's related controller and module manufacturers are also very likely to benefit from this business opportunity in the future.The
 December_2026 Trend Forecast|Technology/Semiconductor Trend Forecast Executive Summary
December_2026 Trend Forecast|Technology/Semiconductor Trend Forecast Executive Summary February_AI Optical Communication|Structural bottleneck of CPO optical interconnection technology in AI mega-scale computing architecture
February_AI Optical Communication|Structural bottleneck of CPO optical interconnection technology in AI mega-scale computing architecture





