五月_Sora 專題|視覺生成式AI技術與應用發展概況解析(上)
自從2022年11月OpenAI開發的聊天機器人ChatGPT上線後帶動生成式AI熱潮,吸引眾多廠商投入開發相關技術與應用,並對諸多行業產生重大影響。回顧其技術演進歷程大致可分為專家系統、機器學習與神經網路、深度學習、大模型等四個階段如下:
- 專家系統:1950年代AI技術開始萌芽,基於規則的專家系統為此時期的技術主軸,它使用複雜的邏輯規則處理包括字元匹配、詞頻統計等簡單任務,應用於機器翻譯及語言對話的內容生成領域,1966年MIT推出的世界上第一台聊天機器人Eliza可視為生成式AI最早期的產品,能夠根據接收到的文本遵循語法規則來模擬與人類使用者對話。由於專家系統存在詞彙量有限、缺乏上下文和過度依賴規則等缺點,生成創造性內容的能力非常有限。
- 機器學習與神經網路:1980 年美國Carnegie Mellon University召開第一屆機器學習國際研討會後興起研究熱潮,於1990年代後其衍伸出神經網路技術,它受到人腦運作模式啟發,能夠以基於規則的系統所不能方式從資料中學習,自此突破AI技術發展瓶頸,開始可以生成逼真和有創意的內容。
- 深度學習:2012年促成生成式AI快速發展的深度學習技術問世,它是基於神經網路的機器學習方法,透過大規模資料特徵學習而對不同應用場景具備很強的自我調整特性,還可以藉由增加層數和節點數以解決對更複雜的問題,進而提升模型的準確性和真實性,並且基於分布運算和 GPU 加速等技術,能夠訓練更大規模資料和參數的模型,成為當前生成式AI技術發展基石。
- 大模型:2015年前發展出理解语言方面的AI技術都是小模型,它們擅長分析任務但沒法生成內容,2017年Google 發佈著名論文《Attention is All You Need》,提出由新式神經網路之注意力機制所構建的Transformer架構,它具備可減少訓練時間的並行性以利研發擁有數十億參數的大模型,2018年OpenAI與Google運用此技術分別開發出具里程碑意義的GPT-1及BERT等AI生成文本模型。此時伴隨如VAE、GAN、Flow、Diffusion、NeRF、CLIP等架構不斷推出,同時開啟視覺生成式AI時代。
AI視覺生成在深度學習問世之前,主要依賴紋理合成或映射等由人工創作特徵之方法,前者藉由分析纹理特性後創建造具有相似性質的新紋理,後者則是將紋理圖像應用到3D模型表面,兩者都很難生成複雜且逼真圖像。2013年起具有非凡的圖片生成能力的GAN與VAE相繼出現可視為圖像生成式AI的重大技術突破,隨後發展的Flow和Diffusion則進一步增強圖像生成的細節和品質,讓使用者能夠透過文本指令生成所需的圖像,這四種技術架構說明如下 :
- VAE : 結合自編碼器和機率建模的概念,用於學習數據的低維度表示並生成新的樣本。它由編碼器和解碼器組成,前者將輸入數據映射到均值和變異數參數,後者使用這些參數來生成新的樣本。並借助潛在變數(Latent Variable)引入隨機性,在生成過程中從潛在變數的分佈中抽樣,然後使用解碼器生成相應的樣本,此舉使其能夠生成具有隨機性的多樣化樣本。
- GAN : 是透過生成器和判別器等兩個神經網絡相互競爭方式進行學習,使得輸出的結果能盡可能模仿訓練的真實樣本,其中生成器會建立新的資料執行個體,判別器則評估這些執行個體的真實性,兩者相互對抗而不斷調整參數,最終使得判別器無法判斷生成器的輸出結果是否真實。
- Flow : 它是設計出能讓已知如何生成樣本分布轉換成訓練資料分布的函數,其特點是兩者間轉換是可逆的。它會訓練特定架構的編碼器,訓練完後取其反函數就可得到能將隨機代碼轉換為影像的生成器。不過為了容易計算反函數,對編碼器設有諸多限制,進而影響生成影像的表現,因此會串接多個生成器,將原本簡單的常態分佈一步一步轉換為複雜的影像分布。
- Diffusion : 是將原始圖片逐漸變成完全雜訊狀態,然後再透過反轉去除雜訊的過程來恢復圖片,使模型學習雜訊圖片和真實圖片間變換關係而能生成出新的高質量圖像,它的靈感來自於流體從高往低濃度區域移動的自然現象,物理的Diffusion是自發且不可逆的現象,但AI的Diffusion是學習反向擴散過程,從雜訊化中得到生成數據的能力。
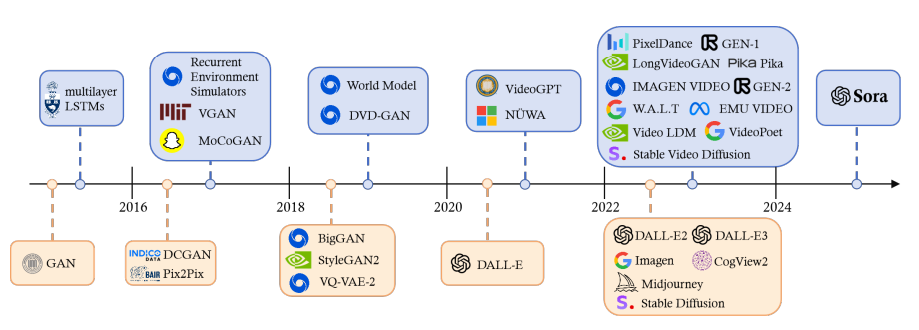
圖1顯示過去十年發展出的視覺生成式AI模型,重大變革為2018年Transformer架構成功用於BERT和GPT等文本生成模型後,研究人員將其結合視覺元件而開發出Vision Transformer和Swin Transformer以用於AI生成圖像與影片領域。同時Diffusion也取得顯著進步,提升U-Nets 將雜訊轉換成圖像之能力。2022年11月ChatGPT上線後大量出現如Stable Diffusion、Midjourney、DALL-E3等文字生成圖片模型,展示AI在創作圖像方面的潛力。不過由於影片製作複雜度很高,從文字生成圖像發展到文字生成影片的AI技術深具挑戰性,導致如Pika、Gen-2等大多數AI生成影片工具僅能創作幾秒鐘短片,直到2024年OpenAI推出能產生長達1分鐘流暢且逼真影片的Sora才突破該限制。
圖1、影像(上)與圖片(下)生成式AI技術發展歷程
資料來源 : Microsoft Research