
May_Sora|Visual Generative AI Technology and Application Development Overview(Up)
Since the launch of OpenAI's chatbot ChatGPT in November 2022, the generative AI boom has attracted many vendors to invest in the development of related technologies and applications, and has had a significant impact on a wide range of industries. The evolution of the technology can be broadly categorized into four stages: expert systems, machine learning and neural networks, deep learning, and large models, as follows.
- Expert system: AI technology began to sprout in the 1950s, and the rule-based expert system was the main technology axis of this period, which used complex logic rules to deal with simple tasks including character matching, word frequency statistics, etc. It was applied to the field of machine translation and content generation of linguistic dialogues, and Eliza, the world's first chatting robot launched by MIT in 1966, can be regarded as the earliest product of generative AI, which can simulate conversations with human users based on the received text following the rules of grammar. Eliza, the world's first chatbot introduced by MIT in 1966, can be considered as the earliest product of generative AI, capable of simulating conversations with human users based on incoming text following grammatical rules. The expert system's ability to generate creative content was limited due to shortcomings such as limited vocabulary, lack of context, and over-reliance on rules.
- Machine Learning and Neural Networks: After the first International Symposium on Machine Learning held at Carnegie Mellon University in the United States in 1980, there was a surge of research, which led to the development of neural networks in the 1990s. Inspired by the mode of operation of the human brain, neural networks are able to learn from data in a way that is not possible with rule-based systems, and have since broken the bottleneck in the development of AI technology. Since then, it has broken through the bottleneck of AI technology and started to generate realistic and creative content.
- Deep Learning: Deep Learning technology, which led to the rapid development of generative AI, was introduced in 2012. It is a machine learning method based on neural networks, which has strong self-adjustment characteristics for different application scenarios through large-scale data feature learning, and it can also increase the number of layers and nodes to solve more complex problems, which in turn improves the accuracy and authenticity of the model, and it can train models of larger scale data and parameters based on techniques such as distributed computing and GPU acceleration, which have become the cornerstone of the current development of generative AI technology. Based on distributed computing and GPU acceleration, it is able to train models with larger scale data and parameters, which has become the cornerstone of the current development of generative AI technology.
- Big models: AI technologies developed before 2015 for understanding language were small models, which were good at analyzing tasks but not generating content. In 2017, Google published the famous paper "Attention is All You Need", proposing the Transformer architecture, which is constructed by the attention mechanism of a new type of neural network, and has the ability to reduce training time and parallelism to facilitate the development of big models with billions of parameters. In 2018, OpenAI and Google utilized this technology to develop landmark AI-generated text models such as GPT-1 and BERT. In 2018, OpenAI and Google used this technology to develop landmark AI generated text models such as GPT-1 and BERT respectively. At this time, with the continuous introduction of architectures such as VAE, GAN, Flow, Diffusion, NeRF, CLIP, etc., the era of visual generative AI was also opened at the same time.
Before the introduction of deep learning, AI vision generation mainly relied on artificial feature creation methods such as texture synthesis or mapping, the former by analyzing texture properties and creating new textures with similar qualities, and the latter by applying texture images to the surface of a 3D model, both of which are difficult to generate complex and lifelike images. 2013 onwards saw the emergence of GAN and VAE, which have extraordinary image generation capabilities, and can be considered a major breakthrough in image generation AI. The subsequent development of Flow and Diffusion further enhanced the detail and quality of image generation, allowing users to generate desired images through textual commands. The four technology architectures are described as follows.
- VAE : Combines the concepts of autocoder and chance modeling for learning low-dimensional representations of data and generating new samples. It consists of a coder and decoder, the former maps the input data to mean and variance parameters and the latter uses these parameters to generate new samples. It also introduces randomness with the help of Latent Variable by sampling from the distribution of latent variables during the generation process and then using the decoder to generate the corresponding samples, which makes it possible to generate diverse samples with randomness.
- GAN: GAN is a neural network that learns through competition between two neural networks such as a generator and a discriminator, so that the output can mimic the real samples of the training as much as possible, in which the generator creates new data executing entities and the discriminator evaluates the authenticity of these executing entities, and both of them are constantly adjusting the parameters against each other, so that ultimately, the discriminator can not judge whether the generator's output is authentic or not.
- Flow : It is a function designed to convert a known distribution of generated samples into a distribution of trained data, with the feature that the conversion between the two is reversible. It trains the encoder of a particular architecture, and after training, it takes the inverse function to get a generator that can convert random codes into images. However, in order to easily compute the inverse function, there are many limitations on the encoder, which in turn affects the performance of the generated image. Therefore, multiple generators are connected to step by step convert a simple normal distribution into a complex image distribution.
- Diffusion: The original image is gradually turned into a completely noisy state, and then the image is restored by reversing the process of removing noise, so that the model learns the relationship between the noisy image and the real image and is able to generate a new high-quality image, which is inspired by the natural phenomenon of the fluid moving from a high to a low concentration area. Physical Diffusion is a spontaneous and irreversible phenomenon, but AI's Diffusion is the ability to learn the process of reverse diffusion and generate data from the noise.
Figure 1 shows the visual generative AI models developed in the past decade. The major change is that in 2018, after the success of the Transformer architecture in text generation models such as BERT and GPT, researchers will develop Vision Transformer and Swin Transformer by combining it with visual components for AI image and movie generation. Meanwhile, Diffusion has also made significant progress in improving the ability of U-Nets to convert noise into images, and in November 2022, ChatGPT was launched, with a large number of text-generated image models, such as Stable Diffusion, Midjourney, and DALL-E3, demonstrating the potential of AI in image creation. However, due to the high complexity of video production, the development of AI technology from text-to-graphics to text-to-movie was challenging, resulting in most AI video generation tools such as Pika and Gen-2 only being able to create short videos of a few seconds, and it was not until 2024 when OpenAI launched Sora, which is capable of producing smooth and realistic videos of up to a minute, that the limitation was broken.
Fig. 1: The development of image (top) and picture (bottom) generative AI technology.
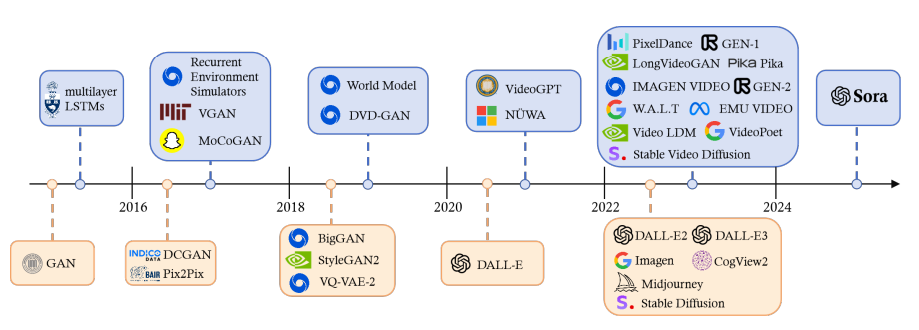
Source : Microsoft Research
 May_Semiconductor Technology|Trends in Semiconductor Process Technology from TSMC Technology Forum
May_Semiconductor Technology|Trends in Semiconductor Process Technology from TSMC Technology Forum May_Sora|Visual Generative AI Technology and Application Development Overview(Next)
May_Sora|Visual Generative AI Technology and Application Development Overview(Next)





