
三月_AI 光通訊專題|從銅到光 AI 資料中心架構剖析
作者:智璞產業趨勢研究所執行副總 林偉智
在 Broadcom 最新法說會中(2026.03.04),執行長 Hock Tan 明確表示,在 400G SerDes 世代下,資料中心內部互連仍可持續使用銅纜,甚至可延續到 2028 年。這番談話迅速在市場引發震盪。長期以來,市場普遍認為 AI 叢集規模快速擴張將加速光學互連的滲透,甚至預期共封裝光學(CPO)將在 2026 年前後進入商業化階段。然而 Hock Tan的說法,等同於為銅纜互連的生命週期再延長數年。這個觀點很快得到部分供應鏈的呼應。高速 SerDes 與主動銅纜(AEC)技術供應商 Credo 在近期訪談中也指出,未來數年 CPO 的滲透率仍可能維持在低個位數水平。該公司認為
Broadcom 與 Credo 的言論,讓市場開始重新審視光通訊技術的導入節奏,無獨有偶在台灣時間3/16舉辦的輝達2026 GTC大會前,預期仍持續展示其矽光子與 CPO 相關技術藍圖,顯示光學互連仍是長期發展方向。過去兩年,AI 基礎建設的爆發性成長使得光通訊產業成為資本市場最熱門的題材之一。800G 光模組需求快速成長,1.6T 模組也被視為下一個世代。然而,隨著銅纜技術在短距離互連上的競爭力被重新確認,到底是光進銅退、光退銅進、還是甚至是光進銅也進?產業逐漸意識到:AI 資料中心的未來並非單純「銅取代光」或「光取代銅」,而是一種更複雜的分層架構。
事實上,銅纜在極短距離傳輸上仍具有不可忽視的優勢。銅纜不需要光電轉換,延遲最低,且功耗與成本均明顯低於光模組。在 GPU 與交換器距離僅數十公分到兩公尺的情境下,銅纜仍然是最經濟且高效的方案。因此 Broadcom 的說法並非否定光通訊,而是指出在 AI cluster 架構中,銅纜仍有其合理的存在空間。這場「銅 vs 光」的討論,其實反映出一個更根本的問題:AI 計算需求正在迫使資料中心網路架構重新設計。當 GPU 數量從數千顆擴展到數萬顆甚至十萬顆時,資料移動(data movement)逐漸成為限制 AI 算力擴張的核心因素。未來 AI cluster 的效率,很大程度取決於互連技術的演進。
技術演進:800G/1.6T 光模塊 與 CPO
AI 資料中心網路正處於高速演進的關鍵階段。隨著生成式 AI 模型規模不斷擴大,資料中心內部跨Node/Rack/Cluster呈現爆發式成長,使得網路頻寬需求持續提升。這種需求推動資料中心互連過去三年的蓬勃發展,從 400G 進入 800G 世代,並逐步邁向 1.6T。目前主流的 800G 光模組通常採用 8 條 112G PAM4 通道,而下一世代的 1.6T 光模組則將使用 8 條 224G PAM4 通道。這一演進不僅意味著單一模組頻寬翻倍,也意味著整個資料中心互連架構正在面臨新的物理限制與工程挑戰。當訊號速率提升至 224G 等級時,傳統銅線在高速傳輸中的訊號完整性問題將顯著增加,使得光通訊在長距離互連中的優勢更加明顯。然而,這並不意味著銅纜會被完全取代。實際上,銅與光之間的競爭並不是單純的技術替代,而是取決於不同應用場景下的多項工程因素。以下四個技術維度,是資料中心在選擇互連技術時最關鍵的考量。
- 延遲(Latency):在資料中心網路中,延遲是影響 AI 訓練效率的重要指標。光通訊系統需要經歷 電訊號轉換為光訊號,再轉回電訊號 的過程,通常還需要加入 前向錯誤校正(FEC) 機制來確保傳輸可靠性。這些步驟雖然能提升訊號品質,但也會增加整體延遲。相較之下,銅纜連接可以直接傳輸電訊號,不需要光電轉換與額外的 FEC 處理,因此在極短距離連接上具有顯著的延遲優勢。這也是為什麼在 GPU 之間或 GPU 與交換器之間的 scale-up 互連 中,銅纜仍然是目前最常見的技術選擇。
- 功耗(Power Consumption):資料中心營運成本的一大部分來自電力消耗,在最近黃仁勳演講中解構AI五層蛋糕缺一層都動不了當中,最底成的就是能源。因此功耗是互連技術的重要評估因素。光模組內部包含雷射、調變器、驅動器與 DSP 等元件,整體功耗通常為數瓦至數十瓦。隨著頻寬提升至 1.6T,單一光模組的功耗甚至可能達到 25 至 35W。相對而言,被動銅纜(DAC)幾乎不需要額外電源,功耗極低,而主動銅纜(AEC)的功耗仍遠低於光模組。在距離僅數公尺的情況下,銅纜在能效方面仍具有明顯優勢。然而,當傳輸距離增加時,銅纜需要更複雜的訊號補償與 DSP 處理,功耗將迅速增加,使得光通訊逐漸成為更有效率的方案。
- 成本與可靠性(Cost and Reliability):成本是資料中心建設的重要因素。光模組內部包含多種精密元件,例如雷射、光學封裝與散熱系統,其製造成本明顯高於銅纜。當 AI cluster 規模達到數萬顆 GPU 時,互連成本將成為整體基礎設施投資的重要組成部分。此外,銅纜結構相對簡單,故障率低,平均無故障時間(MTBF)通常高於光模組。這使得銅纜在資料中心短距離連接中具有較高的可靠性與維護便利性。不過,隨著距離增加,銅纜需要更多的訊號補償與主動元件,整體成本與系統複雜度也會提高,這使得光通訊在長距離場景中逐漸具有成本優勢。
- 距離限制與電磁干擾(Distance and EMI):銅纜的最大限制在於傳輸距離。隨著訊號頻率提升,銅線中的高頻損耗與串擾效應會迅速增加。當通道速率提升至 224G PAM4 時,被動銅纜的有效距離可能縮短至 兩公尺以內,即使使用主動銅纜,其距離也通常限制在 數公尺到十公尺之間。相較之下,光纖幾乎不受電磁干擾(EMI)影響,且可以支援數百公尺甚至數公里的傳輸距離。因此在 rack-to-rack 或 data center fabric 等場景中,光通訊幾乎是唯一可行的技術。綜合目前產業發展趨勢,資料中心光通訊技術的大致時間軸如下表一
表一 插拔式光模塊與CPO預計時程
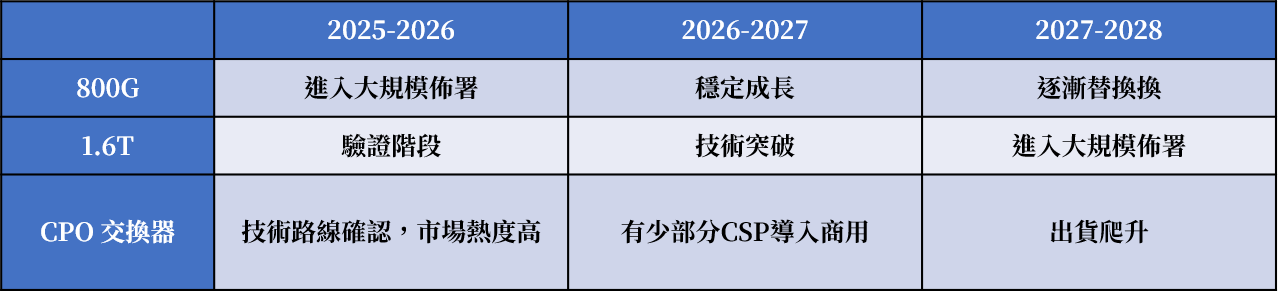
Source: 智璞產業趨勢研究所整理
相對而言CPO(Co-Packaged Optics)並不是一種新的頻寬規格,而是一種光學封裝架構。傳統可插拔光模組(Pluggable Optics)將光引擎封裝在獨立模組中,再透過高速電訊號與交換器 ASIC 相連;而 CPO 則是將光引擎直接整合到交換器封裝中,縮短電訊號傳輸距離,以降低功耗並提升頻寬密度。因此,CPO 並不是用來取代 800G 或 1.6T 光模組,而是未來在部分高頻寬交換器架構中,可能取代傳統插拔模組的封裝以及傳統插拔元件ex. DSP等。也因可能會相關的EIC(電晶片)與PIC(光晶片)會被大幅的取代,因此一直以來都是市場焦點。但在可預見的未來(近三年),插拔光模組仍將是資料中心光通訊的主流架構,而 CPO 則被視為長期可能導入的封裝技術。目前看來,資料中心互連技術暫時並不存在銅纜或光學技術的單一最佳解,而是綜合延遲、功耗、成本與傳輸距離等多項因素搭配不同應用場景需求的工程取捨,銅纜與光學技術將長期共存並形成互補關係。
AI Cluster 的互連架構:從Scale-up 到 Scale-across
目前主流 AI 資料中心已經採用分層互連架構,而非單一技術主導。不同距離與應用場景對互連技術的需求差異極大,使得銅纜與光纖在資料中心中各自扮演不同角色。在現行 AI cluster 中,互連大致可分為三個層級如下表2
表二. 網路層級與技術
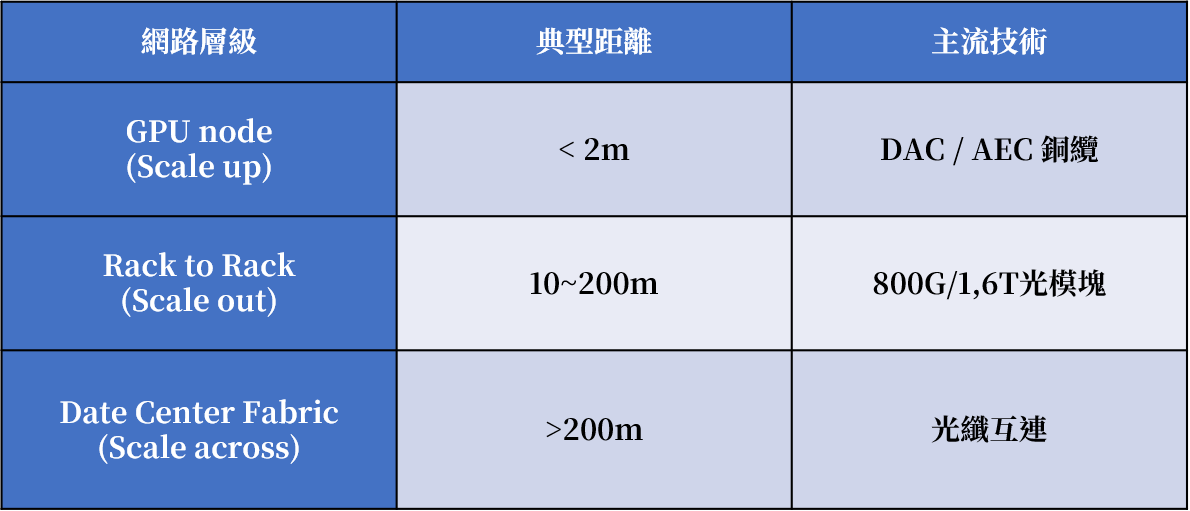
Source: 智璞產業趨勢研究所整理
在 scale-up 層級中,互連主要發生在 GPU node 或單一機櫃內部,例如 GPU 與 GPU、GPU 與 NVLink Switch 之間的連接。此類連接距離通常僅在數十公分至兩公尺之間,因此延遲與功耗成為最重要的設計指標。在這種極短距離場景下,銅纜仍然具有顯著優勢。DAC(Direct Attach Cable)或 AEC(Active Electrical Cable)可以直接傳輸電訊號,不需要光電轉換,因此能提供最低延遲與最低功耗,同時具備成本低與可靠性高的優點。這也是為什麼在目前 AI 叢集架構中,scale-up 互連仍以銅纜為主。然而,銅線在高速訊號傳輸上正逐漸逼近物理極限。隨著資料中心網路速率從 800G(8×112G PAM4)邁向 1.6T(8×224G PAM4),業界普遍認為 224G PAM4 已接近銅線通道的物理天花板。在如此高頻的訊號下,銅線會受到訊號衰減(attenuation)、反射(reflection)、串擾(crosstalk)以及抖動(jitter)等問題影響,使訊號品質快速惡化。即使透過更複雜的 DSP 補償訊號損耗,所帶來的功耗與熱密度也會迅速上升。這也是業界常提到的「銅線牆(Copper Wall)」現象。
當互連距離延伸至 scale-out 層級時,情況便開始改變。Scale-out 指的是 rack-to-rack 或 pod-to-pod 的網路連接,其距離通常介於數十公尺至數百公尺之間。在這種距離下,銅纜的訊號衰減與串擾問題迅速惡化,因此光通訊成為更合理的解決方案。目前 AI 資料中心主要採用 800G 可插拔光模組作為 rack-to-rack 的互連技術,而未來將逐步升級至 1.6T 光模組。這種升級不僅僅是網速的提升,更是為了維持 AI 叢集在大規模 GPU 部署下的運算效率。隨著模型訓練所產生的GPU之間的溝通需求快速增加,交換器與 GPU 之間的通訊頻寬需求也同步成長,使高頻寬光模組成為維持 AI cluster 線性擴展的重要基礎設施。在更高層級的 scale-across 網路中,資料中心需要連接不同的 AI Rack、Cluster 或資料中心區域,形成整體的運算 fabric。這一層級的傳輸距離通常達到數百公尺甚至更遠,因此光纖幾乎是唯一可行的互連技術。隨著 AI cluster 規模持續擴張,這一層級的光通訊需求也在快速成長,成為整個光通訊產業最主要的需求來源。在這樣的分層架構下,銅與光並非互相取代,而是形成明確分工:銅纜主要負責極短距離的 scale-up 連接,而光纖則承擔 scale-out 與 scale-across 的長距離高速傳輸。這也解釋了為何 Broadcom CEO Hock Tan 強調銅纜仍可在短距離互連中持續使用。這種說法並不代表光通訊需求減弱,而是反映了資料中心互連的工程邏輯:在最短距離場景中,銅仍然具備成本與功耗優勢。
在未來架構演進中,CPO交換器可能扮演新的角色。其最可能的應用場景並非目前已經光學化的 scale-out 網路,而是目前仍以銅纜為主的 scale-up 互連。換言之,CPO 的真正目標是讓 GPU 與交換器之間的極短距離連接逐步光學化。然而,由於 CPO 在可靠性、可維修性與供應鏈成熟度方面仍面臨挑戰,例如雷射壽命、系統維修成本以及封裝複雜度等問題,產業普遍認為其大規模導入仍需要數年的時間。因此,在可預見的未來,AI 資料中心互連將持續維持 銅纜與光通訊並存的分層架構:銅纜負責最低延遲的短距離互連,而光通訊則支撐大規模 AI 叢集所需的長距離高頻寬網路。
圖一. AI集群互連架構
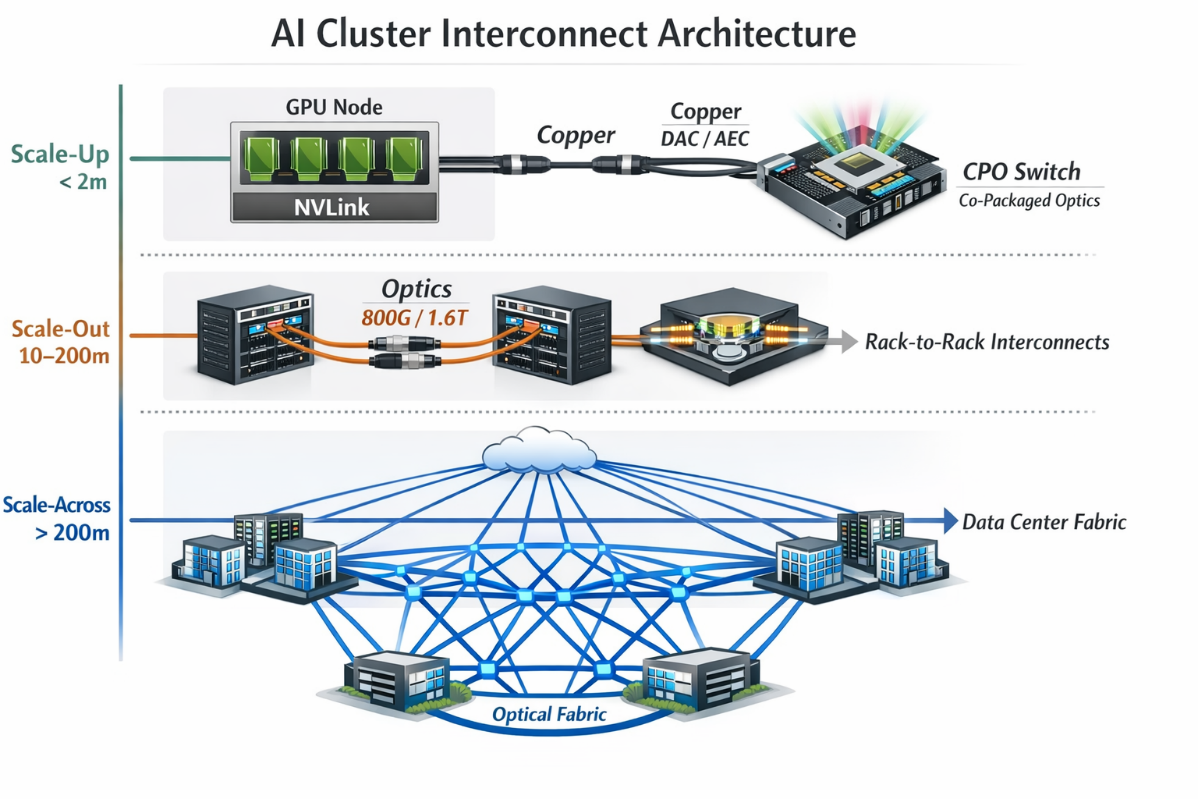
Source. 智璞產業趨勢研究所整理
結論
輝達 GTC 大會一直是 AI 基礎建設技術的重要風向球。從過去幾年的發展來看,輝達不僅在 GPU 架構上持續突破,也逐漸將重心延伸至整個資料中心平台,包括 NVLink、Spectrum-X 交換器與 AI 網路架構。在即將到來的 GTC 2026,大會可能透露幾個值得關注的訊號。首先是 NVLink Fabric 的進一步演進。隨著 GPU 數量增加,NVLink 已從單一伺服器內部互連逐步擴展到整個叢集的高速網路。未來 NVLink Fabric 是否會導入光學互連,將成為產業觀察的重點。其次是 Spectrum-X 交換器的發展方向。作為 AI 資料中心的重要網路平台,Spectrum-X 很可能在未來世代中採用更高頻寬的光通訊技術。另一個可能的焦點是第二代 CPO 交換器。若輝達在 GTC 上展示相關原型產品,將代表光學封裝技術正在逐步走向成熟。這不一定意味著 CPO 能在2026立即進入大量生產,但將顯示產業正在朝該方向前進。
而以供應鏈的角度,如下圖二,我們可以可關注三個主要方向:
- 高速銅纜與 SerDes 技術。隨著銅纜在短距離互連中的角色被重新確認,相關供應商仍具成長潛力。
- 800G 與6T 光模組。隨著 AI cluster 規模持續擴張,光模組需求將保持強勁成長。
- 雷射光源與 InP 材料供應鏈。高速光模組的核心元件是雷射,而 InP 材料產能有限,使其成為未來光通訊產業的重要瓶頸。
總體而言,AI 光通訊產業正進入一個長期成長周期。未來資料中心網路的關鍵,不再只是單一技術,而是整個互連架構的重新設計。銅與光不是零和競爭,而是兩者共同構成的分層互連世界。以現在的觀察銅不會消失,而是「縮短距離」並將繼續在 scale-up 層級發揮作用,而光則在 scale-out 與資料中心骨幹網路中扮演關鍵角色。
圖二. CPO 產業鏈

Source. 網路; 智璞產業趨勢研究所整理
 二月_AI光通訊專題|AI 超大規模運算架構下,CPO 光互連技術的結構性瓶頸
二月_AI光通訊專題|AI 超大規模運算架構下,CPO 光互連技術的結構性瓶頸 四月_AI 光通訊專題|全光交換OCS(Optical Circuit Switching)在Scale-across 的機會與物理極限
四月_AI 光通訊專題|全光交換OCS(Optical Circuit Switching)在Scale-across 的機會與物理極限





