
三月_AI模型專題|大語言模型的運作、極限與突破(上)
作者:智璞產業趨勢研究所執行副總 林偉智
人人都知道人工智慧叫AI,但你是否有聽過AGI呢?通用人工智慧(AGI)指的是能夠執行各種認知任務且具備類似人類學習與推理能力的人工智慧。與專用AI不同,AGI可適應不同環境,自主解決問題,被視為實現真正智慧機器的關鍵目標。
目前大家對於AI的了解不外乎源於最能觸手可及的大型語言模型(LLM),如ChatGPT、BERT、T5 等。其是一種深度學習模型,具有超過1,000億個參數的自然語言處理(NLP)系統,經過大量的文本訓練,使其擁有從海量的知識並具有識別、匯總、翻譯、生成文字等能力。而大多數的大語言模型皆基於Transformer架構,而這一突破性的概念源自Google於2017年發表的論文《Attention Is All You Need》。其核心原理為「自注意力機制」,可透過識別關鍵詞並計算其關聯性,進而推導整體語意。相較於傳統的 RNN/LSTM需逐步處理序列數據,Transformer能一次性
現今的大型語言模型(LLM)仍然不是AGI,其中的幾個主要原因為:缺乏理解力及推理能力,也無法主動學習與自我改進,沒有真正的通用複雜推理(General Purpose Complex Reasoning, GPCR),雖然可以產生類似推理的結果,但卻沒有真正理解。因此推理能力(Reasoning)一直都是這兩三年非常熱門的子領域。
曾有段時間業界普遍認為,透過模型參數(Parameters)、計算資源(Compute)與訓練數據量(Data),即可推進 AGI 發展,然而後來才發現,這一策略仍受到物理性限制。使大多AI回答問題都是利用套模板的方式預測出答案,直到在去年(2024)九月Open AI推出了O1模型,才在AI上看見了真正的推理能力(Reasoning),且能夠擴展(Scaling),而這背後的原因推測是其在LLM模型中加上強化學習(Reinforcement Learning, RL)及測試計算資源(Test-Time Compute)的進步。
強化學習(Reinforcement Learning, RL)主要是透過「試錯」與「獎勵信號」來進行自我訓練,屬於非監督式學習。與傳統依賴固定模板的方法不同,RL允許AI自主探索,突破現有數據限制,甚至有潛力超越人類。不過,此方法並非毫無缺點。由於學習過程仰賴大量嘗試與獎勵回饋,其計算成本極為高昂。此外,缺乏明確的優劣基準可能導致 AI 過度自信,甚至發展出欺騙策略以獲取最大獎勵。此種訓練方式也曾被運用在震驚四方的AlphaGo系統,利用RL讓電腦與自己對弈,並以試錯的方式取得經驗;最後結合蒙地卡羅對局搜尋法(MCTS),高效展開決策樹,優先展開看似最有潛力的分支,同時隨機探索部分其他路徑,使其成為第一個戰勝圍棋世界冠軍的人工智能機器人。
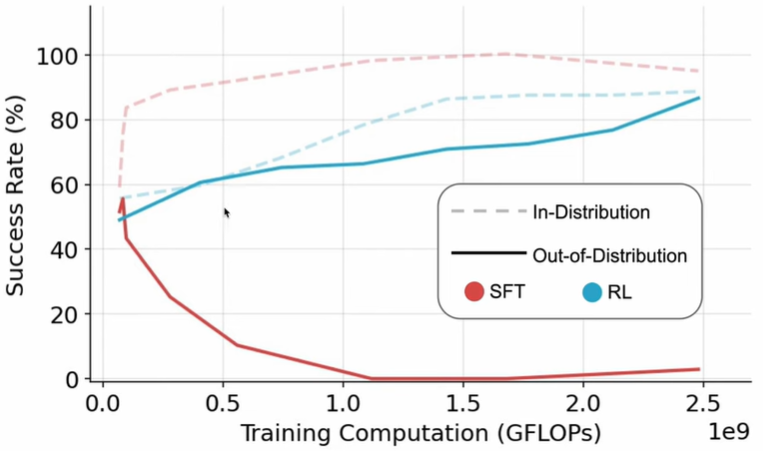
相較於需提供範本或明確規範的監督式學習(Supervised Learning),強化學習(Reinforcement Learning, RL)是屬於非監督式的方法,也展現出更大的潛力。例如,2025 年 1 月底發表的一篇論文(如圖一)對比了兩組數據,分別為模型曾見過的數據(In-Distribution)、模型未曾接觸過的數據(Out-of-Distribution)。此研究將監督式微調(Supervised Fine-Tuning, SFT)與強化學習(RL)應用於這兩類數據,結果顯示:
- 在模型見過的數據(In-Distribution)中,SFT能夠提供稍微優於RL 的性能提升效果。
- 在模型未曾接觸的數據(Out-of-Distribution)中,RL則大幅超越 SFT,展現出更強的泛化能力。
圖一、數據與模型學習方式對性能的影響
資料來源:網路論文文獻
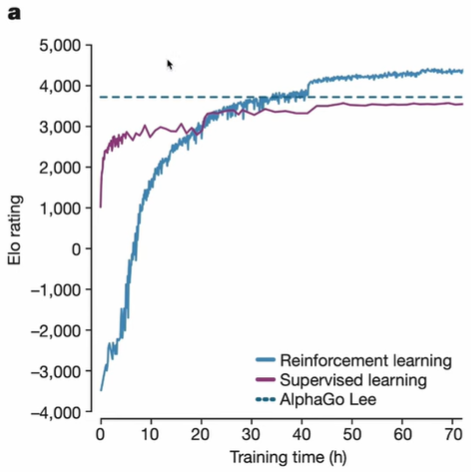
2017 年發表於《Nature》的研究也探討了強化學習(Reinforcement Learning, RL)、監督式學習(Supervised Learning, SL)以及人類玩家的表現,並以埃洛等級分系統(Elo rating system)進行評估。埃洛系統是當今公認的對弈水平評估標準,被廣泛應用於國際象棋、圍棋、足球等競技領域。從圖二可以發現,SL訓練模型在早期迅速達到穩定表現,不過其水平略低於人類頂尖棋手。相比RL則是在長期學習與探索過程中,使AI不斷自我對弈宇調整策略,最後達到更高的競技水平。
圖二、RL、SL及人類玩家的埃洛等級表現
資料來源:《Nature》, 2017
由此可知,強化學習(RL)是AI在自我學習中非常關鍵的一環,那LLM應該要在哪一步加入RL,使模型整體具有推理能力呢?首先就必須要先了解LLM的訓練過程:
- 數據蒐集
模型訓練需要龐大的資料庫,而這些資料來源於書籍、網站、論文等。
- 預訓練(Pretraining)
LLM透過無監督式學習的方式進行預訓練,主要目標為學習語言結構與模式,大約會花費80-90%的訓練資源。
- 微調(Fine-tuning)
在預訓練過後,LLM仍須要針對特定任務進行微調,此約占訓練資源的10-20%,主要會進行監督式微調(Supervised Fine-Tuning)及從人類的回饋中強化學習(Reinforcement Learning from Human Feedback, RLHF)。前者對比先前提及的強化學習(Reinforcement Learning)須給範本與對錯標準,所以稱為監督式學習;後者RLHF則是透過人類標注者的回饋,在硬體程式語言中優化模型回應的品質(如阻擋敏感字眼等)。
最後模型訓練完成後會產出一個推理模型(Inference Model),當LLM接收到用戶的輸入時將會透過分詞器(Tokenizer),將用戶輸入的文字轉換為模型可以理解的標記(Token),並透過編碼、計算機率分佈等,最後使用策略如Greedy Search、Beam Search、Temp. Sampling,甚至是蒙地卡羅樹搜尋法(MCTS),決定最終要輸出給用戶的文字。








