
四月_ChatGPT探討|ChatGPT的技術發展與優勢剖析
ChatGPT於2022年11月由OpenAI推出的人工智慧聊天機器人程式。OpenAI是2015年由Elon Musk與Samuel H. Altman共同創立的非營利性人工智慧公司,總部位於舊金山市,其成立宗旨在於將解決人類在科技上遇到的困境與問題作為未來人工智慧研究創造基礎。該公司由世界各地頂尖研究人員與學者組成,透過機器學習與學術研究開發人工智慧技術,為全球社會創造價值也幫助人類對自然環境更加充分的理解。2018年Elon Musk考量Tesla的自駕技術發展與OpenAI可能衍生利益衝突而退出董事會,之後Altman一肩扛起公司營運。因無法負擔長期訓練模型的高額費用,2019年OpenAI轉向有限營利模式,重組後不久即獲Microsoft投資10億美元以取得部分AI技術商業化的優先權,並促成雙方合作為Azure雲端平台服務開發人工智慧技術。當ChatGPT爆紅後,2023年Microsoft再注資數十億美元,並將旗下搜尋引擎Bing和瀏覽器Edge導入ChatGPT的語言模組,藉此搶占龐大的搜尋市場商機。此舉讓Google深感威脅,創辦人Sergey Brin與Larry Page還為此回鍋督導人工智慧技術研發。目前OpenAI主要開發的人工智慧技術包括:
- 機器學習:自動化學習和應用新知識以改善人工智慧表現。
- 深度學習:可開發更深入和多樣化的應用,更有效理解並模擬人工智慧的行為。
- 自然語言處理:更加深入理解和模擬人類的言語行為。
- 自主式行為:理解、模擬並建立人類之行為模式。
表2、三種GPT模型的重要參數比較
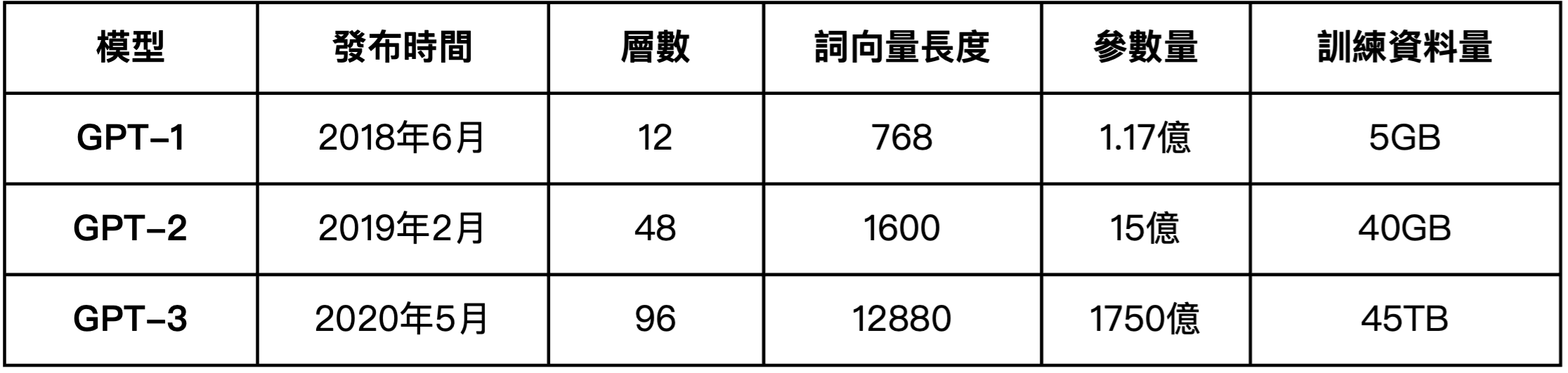
資料來源 : OpenAI
因為訓練得到的模型不是非常可控,回饋到生成模型中之訓練資料分佈便是影響生成內容品質最重要的因素。有時候開發者希望模型並不僅僅只受訓練資料的影響,而且還是人為可控以保證生成資料的有用性、真實性和無害性。於是OpenAI使用人類反饋強化學習(RLHF)技術改進GPT-3模型,稱為InstructGPT。其方法是根據用戶向應用程式開發介面(API)提交的提示,由標記員向模型提供示範行為並對輸出進行排名來進行微調。InstructGPT可以更好地遵循人類指示,有害內容輸出也大幅降低。它雖然僅具有13億個參數,遠低於GPT-3模型,但研究人員使用自然語言處理效能評估方法來衡量其能力而發現兩者差不多。
ChatGPT是由GPT-3延伸出的GPT-3.5模型所製作,也是使人類反饋強化學習來訓練該模型,其訓練程序分成三步驟,如圖2所示。首先根據採集的資料集對GPT-3進行有監督的微調(SFT),其次是收集人工標注的對比資料來訓練獎勵模型(RM),最後是使用獎勵模型作為強化學習的優化目標,利用近端策略優化(PPO)演算法微調模型。ChatGPT與InstructGPT的資料收集方法略有不同,並加入強化學習近端策略優化,可以理解成在人腦思維的基礎上加入人類回饋系統,因此成文效果更真實、編碼能力更強而模型的無害性有些許提升。ChatGPT的技術優勢是採用自注意力機制,能夠更好理解語境並在產生文本時考慮到先前的對話內容,除了可快速產生高品質的文本外,還不需要任何額外的訓練就能在多種不同的領域中使用,並可進行如情感分析、關係推斷和情境建模等多種對話任務。而其技術仍有侷限性需要突破,包括:(1).ChatGPT輸出文本時效性受到OpenAI的模型資料庫更新頻率、資料來源影響,故可能出現不符現況之狀況。(2).ChatGPT只能基於現有資料輸出文本資訊,若資料庫欠缺特定領域資訊則生成的文本勢必不夠專業。(3).OpenAI訓練ChatGPT時通常使用大量經過人工或自動的過濾來排除生成不合適內容的文本,然而隨著模型的公開使用,有可能會出現某些不合適的資料被用於生成結果而導致準確性下降。
圖2、GPT-3.5與InstructGPT模型的訓練程序
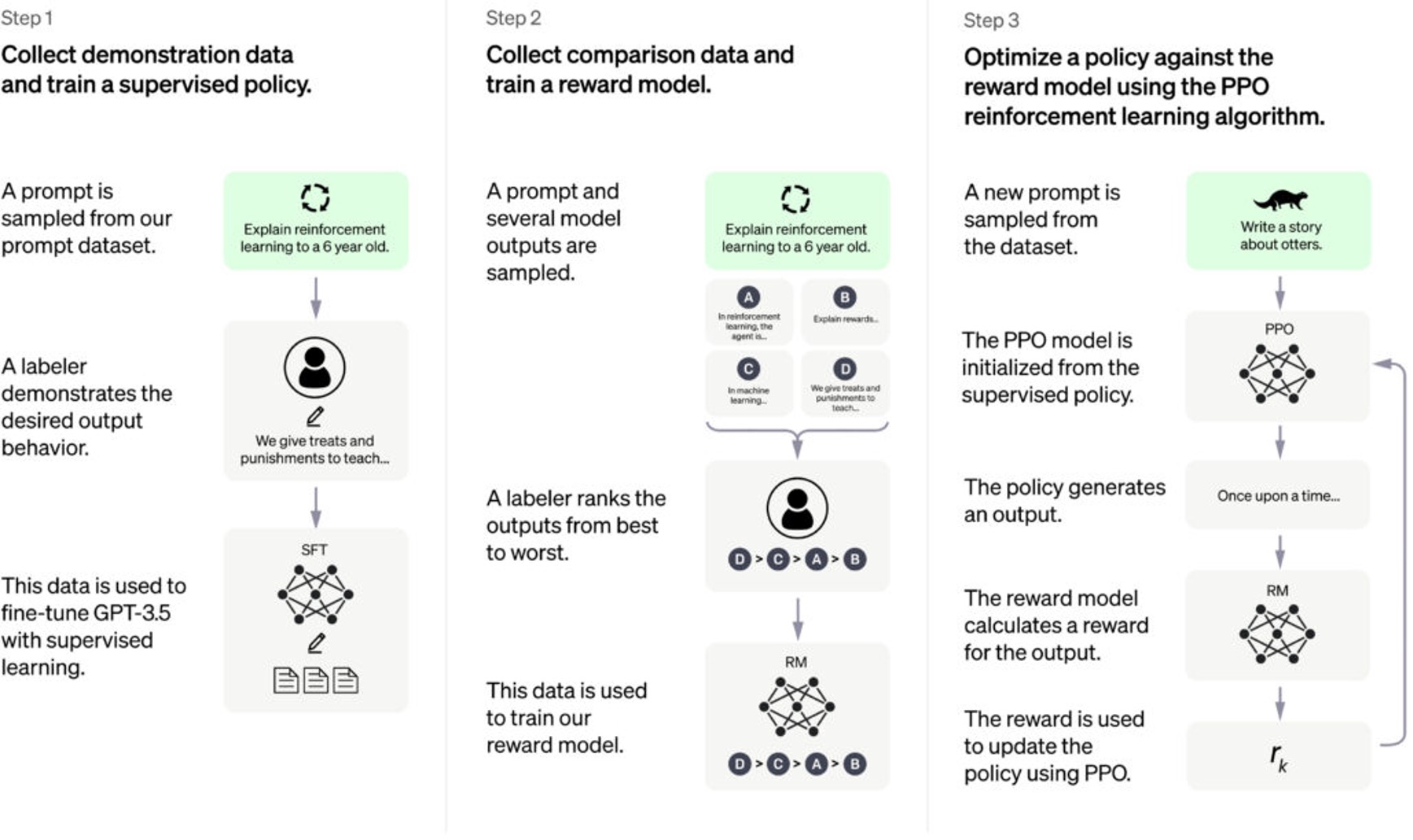
資料來源 : OpenAI








