
六月_端午節專題|從 Google 發布《From AGI to ASI》看 AI 發展趨勢與限制
從 Google 發布《From AGI to ASI》看 AI 發展趨勢與限制
作者:智璞產業趨勢研究所執行副總 林偉智
在過去一年,「AGI(Artificial General Intelligence 通用人工智慧) 即將到來」的聲音不斷出現在大眾面前,而且越喊越近。Elon Musk 把「比最聰明人類更聰明」的 AI 押在2026年(前一年講的還是 2025);Anthropic的 Dario Amodei 則形容那將是 「資料中心裡的天才之國」,同樣指向2026。與此同時,一批原本站在頂尖機構核心的研究者陸續出走、自立門戶,OpenAI 共同創辦人暨前首席科學家Ilya Sutskever,創立了直指終局的Safe Superintelligence(安全超智慧)。資本與頂尖人才正大規模往「AGI、乃至 ASI(超人工智慧)」的方向集結。有趣的是,把這些預測並排,就會發現兩件事。首先連最樂觀的Musk都在悄悄把日期往後挪;再則,業界對 AGI的時程毫無共識。更微妙的是,他們連「AGI 到底指什麼」都各執一詞。正是在這樣的喧囂中,Google DeepMind 於 2026 年 6 月初發表的《From AGI to ASI》格外吸引了我的注意。查了資料才發現,DeepMind執行長 Hassabis、與作者之一的 Legg,恰恰是上述時程戰裡相對謹慎的一端。對我而言,這是一份「地形圖」,不是一份「時間表」。它提供的不是預測,而是 AI 目前整體的地形樣貌,以及一套觀察 AI 發展的框架。因此本文便以這份報告為本,做一次「趨勢」與「限制」並重的梳理。
- 成長的引擎與它的不確定性
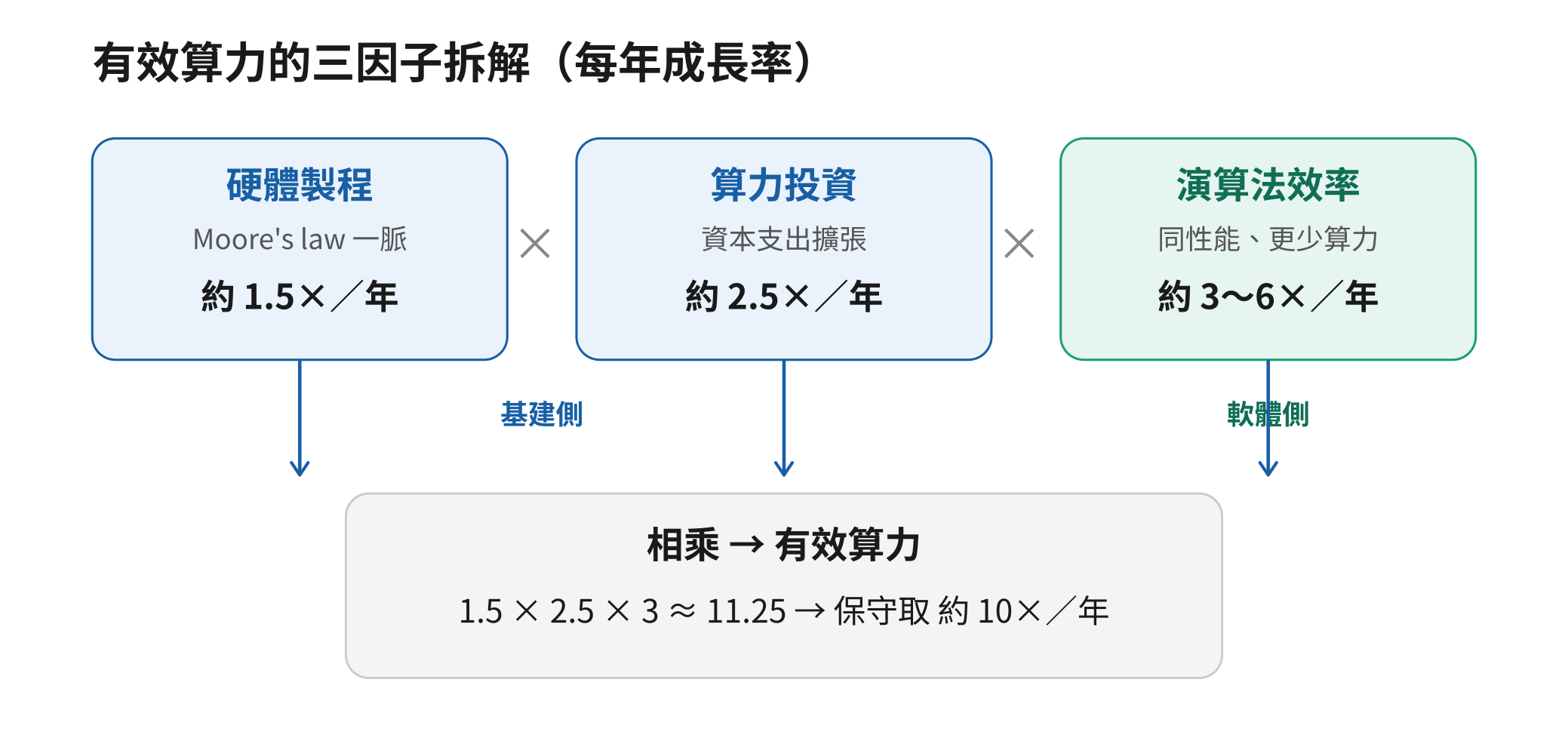
過去一年,AI 最明顯的躍進不在於「回答得更好」,而在於它開始能「自己做事」,即Agentic AI走入實用,能自主拆解任務、呼叫工具、連續推理數十步,替使用者完成過去需要一整個流程才能搞定的工作。相信實際部署/使用過 agent 的人都有兩種並存的體感:一方面,它的能力是肉眼可見地往上跳;另一方面,因為它好用,使得用量增加而跑起卻越來越「貴」或越來越「慢」。一個 agent 動輒吞掉巨量運算、長篇推理,回應之前還常常在「等」。這種「能力快速上升、代價卻未隨之輕鬆下降」的矛盾體感,一邊反映了背後那部驅動能力成長的引擎,一邊也預告了這部引擎開始遇到的阻力。《From AGI to ASI》用「驅動力」與「阻力」作為全篇的兩條主線。報告把這股驅動力歸結為一個指標:有效算力(effective compute)的年成長率,並估計它約為每年十倍,這個數字是整篇報告的地基,也是後面所有「限制」討論的對照基準。而這個十倍,其實是下面三個因子相乘出來的:
- 硬體製程的進步(即 Moore’s law),讓每一美元能買到的算力,過去六十年以每年約 1.5 倍的速度成長。
- 算力投資的擴張:過去十年雲端與 AI 業者投入硬體的金額,以每年約 2.5 倍增加。前兩者相乘,使得投入最大型訓練的算力,十年來約以每年 4 倍成長。
- 最容易被忽略的一項演算法效率:達到同樣性能所需的算力持續下降,速度約為 Moore’s law 的兩倍(每年3倍),近期更有研究估計高達每年6倍。三者相乘,報告得出每年約十倍的有效算力成長。
但其中的「十倍」是估計,不是定論。報告在註腳坦白,三個因子各有不小的不確定性,相乘之後「實際成長率可能明顯更大」;它甚至把算出來的 11.25「保守地」說成 10。換句話說,這個撐起整篇報告的數字,比較像是一個方向性的判斷,而非精準預測。這也正是全篇反覆強調「不確定性」的起點。
而真正讓「能力上升、代價卻下不來」的關鍵阻力,並不在這三個因子本身,而在於有效算力能否被實際利用,也就是當資料在記憶體與運算單元之間搬移的時間成為瓶頸,再多的理論算力也轉不成實際性能。這正是報告在後段點名的「記憶體頻寬與互連瓶頸」。換句話說,這部引擎目前轉速極快,但它能轉多久、轉速會不會掉、以及轉出來的力道能不能真正傳遞到輪上,正是後面所有「限制」討論的核心。
圖一、有效算力因子拆解(每年成長率)
Source: From AGI to ASI;智璞產業趨勢研究所整理
- AGI、ASI、UAI 的定義與討論
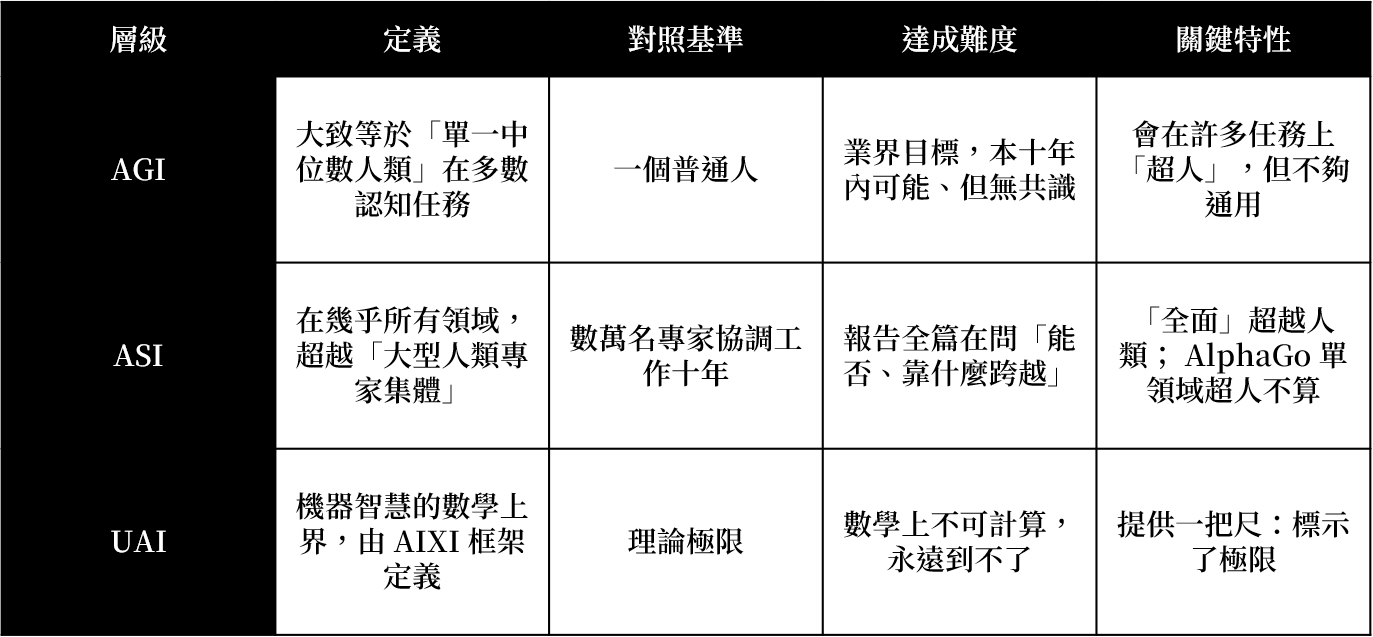
如前所言,業界連AGI的統一定義都各執一詞,也就是 Musk 說的 AGI、Altman 說的 AGI、黃仁勳說的 AGI 其實可能都不是同一回事時,因此所謂「AGI 何時到來」的爭論,有一大半其實是定義之爭。《From AGI to ASI》清楚的給出三個層級的座標定位。但這是報告中Google DeepMind為了討論方便而採用的定義,並非業界公認標準,而且其中的 UAI 理論錨點,正出自作者群中的 Hutter 與 Legg 本人所建立的 AIXI 框架。換言之,報告某種程度上是用自家理論當作丈量智慧的尺。
- AGI(通用人工智慧):報告刻意採用一個樸實的標準,即「大致等於單一中位數人類」在多數認知任務上的水準。注意是「中位數人類」,不是頂尖專家。報告還補了一個常被忽略的觀察:由於今天的 AI 在不少面向已經超越人類,第一個真正的 AGI,一誕生就會在許多任務上是「超人」的,它只是還不夠「通用」而已。
- ASI(超人工智慧):報告把門檻設得很高。它指的不是「比一個專家強」,而是「在幾乎所有領域,超越大型人類專家集體」。更具體說成「可靠地勝過數萬名良好協調、工作十年的專家」,大約是一整個研究領域或一家大型企業的產出。值得一提的是,像 AlphaFold(2024諾貝爾獎使用的AI 模型)、AlphaGo(2016圍棋打敗人類最高段的棋手) 這種單一領域的超人系統,在報告的定義下不算 ASI,因為 ASI 必須是「全面」的超越。
- UAI(通用 AI,Universal AI):這是理論上的終點。機器智慧的數學上界,由所謂的 AIXI 框架定義。它的重點不在於「會不會實現」(就像物理的光速一樣,它在數學上不可計算,永遠到不了),而在於它提供了一把尺:讓我們知道智慧是一條連續光譜,從 AGI、ASI 一路指向這個不可達的極限。正因為是連續光譜,報告才不需要替 AGI 和 ASI 訂出銳利的分界線,重點是兩者之間有「顯著的差距」就夠了。
這三層定義給了我們一個重要的視角:從 AGI 到 ASI,不是一個開關,而是一段距離。而報告真正想問的,正是「這段距離能不能被跨越、靠什麼跨越、又會被什麼擋住」。同時,我認為報告埋下一個與台灣產業切身相關的伏筆。它指出人工智慧有一項生物智慧沒有的根本特性:我們完全掌握它的程式碼。由此衍生出幾個「會隨算力放大」的優勢,可以無損複製(連同記憶狀態一起複製)、可以在不同硬體間遷移、可以把學習經驗高頻寬地共享。這意味著什麼?意味著當你有足夠的算力,就能把「一個 AGI 等級的專家」複製成上百萬份、平行運作。這個看似抽象的特性,正是後面「靠規模就能逼近超智慧」這條路徑的微觀基礎。而每一份複製、每一次平行運作,吃的都是實打實的運算與記憶體資源,也呼應了我一直說的:只要AI不死,算力與記憶體的需求就永遠不夠用;倘若 AI 已死,算力與記憶體的需求才沒人在乎。
表一、Google DeepMind AGI/ASI/UAI 三層定義對照
Source: From AGI to ASI;智璞產業趨勢研究所整理
- Scaling 能與不能:能力會持續,但「跳級」的代價正在失控
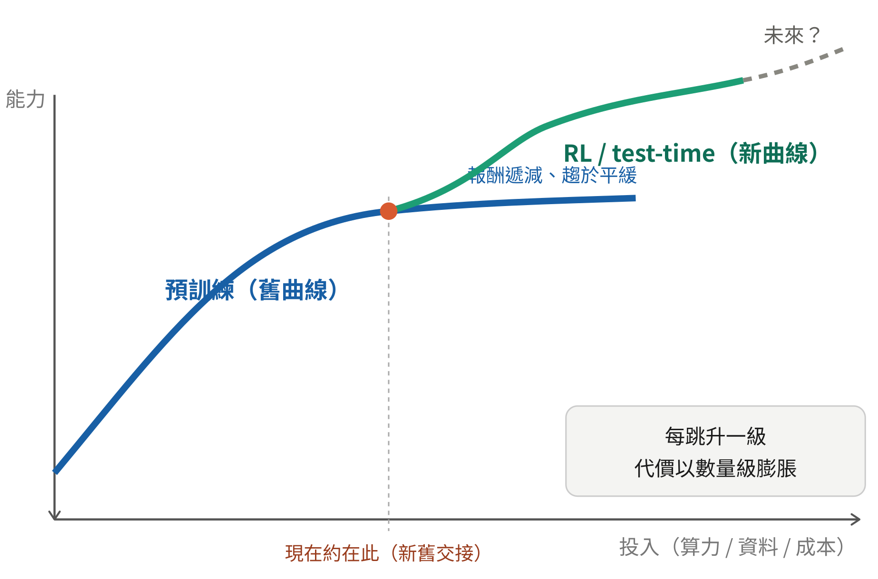
如果說有效算力是引擎,來驅動模型成長,那 scaling law可以比喻為這部引擎的「使用說明書」。它描述的是:當你按比例放大模型、資料與算力,性能會以可預測的方式提升。過去十年 AI 的躍進,幾乎都是照著這張說明書走出來的。但 2025 年起,這張說明書本身成了業界最大的辯論。
在《From AGI to ASI》的判斷其實相當克制:純粹放大「單一模型」,不足以抵達 AGI、更別說 ASI。這一點,理由是,有效的 scaling 從來不是「無腦的暴力放大」,而是要靠聰明的設計搭配好的模型架構、好的訓練方法,來提升學習效率,讓模型用更少的資料和算力學到更多。但這些聰明的設計在幫你省成本的同時,也悄悄設下了能力的天花板。換句話說,報告認為要持續突破,質的創新(新架構、新演算法)是必要的,光靠量的堆疊不夠。但報告留了一條後路,這條後路很關鍵。它說:就算「單一模型」的智慧停滯了,只要有效算力繼續成長,你仍然可以靠「跑更多份、跑更快、組成集體」來推升整體能力,把一個 AGI 複製成上百萬份、平行協作,很難說這不算是對 AGI 的一次階躍。所以報告對 scaling 的結論是雙層的:對「單一模型變聰明」,scaling 不夠;對「整體系統變強大」,scaling 可能就夠。
Scaling議題,在過去的一年許多業界大神也不斷地在討論,我認為外部的業界辯論,焦點其實不是「scaling 還靈不靈」,而是「該 scale 什麼」。 一端是 scaling 假說最重要的推手之一、OpenAI 共同創辦人 Ilya Sutskever。他在 2024 年底公開表示 「我們所知的『預訓練』將會終結」。但他針對的是「預訓練」這一條特定路徑,而非 scaling 本身。理由是算力成長很快,但並沒有足夠的資料。換句話說,是「燃料(資料)快用完了」,不是「放大這件事失效了」。他真正的主張,反而相當親 scaling:「scaling 對的東西,現在比以往任何時候都更重要」。也就是把力氣從預訓練,轉向 RL、test-time 等新方向。另一端是 Anthropic 執行長 Dario Amodei,他代表「現行典範的放大仍有續航力」的樂觀派:放大神經網路(規模、資料、算力)會持續、可靠地增強 AI 能力,並預期 AI 在 2026 或 2027 年於某些領域達到或超越人類水準。兩人的分歧,與其說是「看多 vs 看空」,不如說是「繼續放大現行典範」與「把 scaling 轉向新範式」之間的路線之別,恰恰呼應了報告所列的兩條不同路徑。
那麼,scaling law 到底還在不在?我不是專業科研人員,可能無法作出精準的判斷,但與其問「在不在」,不如看清它的形狀已經變了。過去(2024年底)那條主力曲線,確實遇到了瓶頸:資料逼近耗盡、模型越做越大,但報酬卻在快速下降。然而,當 RL(強化學習)被引入、test-time compute(推論期運算,也就是讓模型「思考」更久)開始發揮作用,等於是在舊曲線之外,又開出了一條新的成長曲線。換句話說,AI 的進步並沒有停下,只是動力來源從「把模型練得更大」,部分轉移到了「讓模型想得更久、學得更巧」。但真正的關鍵在於“代價”。不論是舊曲線還是新曲線,要讓模型「跳升一個能力等級」,所需投入的資料與算力,都在以指數級的速度膨脹,這一點,到了 2026 年看得更清楚:光是 RL 訓練的算力,從 o1 到 o3 一代之間就增加了超過十倍。它不是撞上一堵牆,而是踏上了一道越來越陡的斜坡,每往上爬一階,成本就翻上一個量級。這正是第一節那個矛盾體感(能力上升、代價卻下不來)的根源,也讓 scaling 之爭的重心,從「行不行」轉向了「划不划算、撐不撐得住」。更值得注意的是,這條新曲線自己也在進化。這份報告發表於 2026 年中,但 RL 這條路在報告成文後又往前跨了一步:焦點正從「演算法」轉移到「環境」。前沿模型越來越需要在擬真的模擬環境裡,透過試誤來學習,而不再只靠靜態資料(也沒有足夠的靜態資料);於是「RL 環境(RL environments)」成了新的競逐焦點。2026 年,企業問的不再是「哪個模型最好」,而是「你的模型是在哪個環境裡訓練的」。當現成資料見頂,下一步就是「製造」或「合成」資料,進而打造環境、讓海量 agent 在其中反覆試誤,而每一步都吃下更多的推論算力與記憶體。所以,即使是認為預訓練已走到盡頭的 Ilya,他的解方也不是放棄算力,而是「把算力用在對的地方」。從預訓練,轉向 RL、test-time 與新的學習範式。換言之,無論你站在哪一條路線,「算力會持續是稀缺資源」這個結論都不會改變;改變的,只是它被花在哪裡——而 2026 年的答案,正越來越指向「推論」與「環境」這一端。
圖二、Scaling law 的現況與未來(示意圖,僅示趨勢,非實際數據)
Source: From AGI to ASI;智璞產業趨勢研究所繪製
如果說前面談的是「引擎」與「燃料」,這裡就延續《From AGI to ASI》報中的邏輯,來談「路線圖」。從報告中有四條他們認為可能從AGI到ASI的技術路徑。要先強調的是:這是假設我們已經有了AGI後的情境,這四條並非互斥,而是可以並行、甚至彼此加成。它們之間有一個耐人尋味的共通點,可預測性是遞減的:第一條有歷史數據可外推,後三條則越來越只能憑推測。這個「可預測性遞減」的特性,後面會看到,正是 AI 類股估值容易劇烈擺盪的根源之一。
- 路徑一:擴大規模(Keep Scaling),更大的模型、更多的資料、更多的算力。它的最大特色是「可外推」,是四條裡唯一能用歷史數據擬合預測模型的。所需資源最直接:算力、能源、資料,以及承載這一切的硬體。
- 路徑二:典範轉移(Paradigm Shift),當現行架構撞到天花板,改用全新的架構或學習方式,如以 RL 為核心的模式,或是更前沿的新型運算硬體(主打能源效率的突破)。它的特色是「不可預測」:突破何時發生、長什麼樣,無法事先得知。所需資源偏向研究人才與基礎研究,而非單純的硬體堆疊。
- 路徑三:遞迴自我改進(Recursive Self-improvement)。 AI 用來加速 AI 自身的研發,設計更好的演算法、更好的晶片,形成「越強的 AI 造出更強的 AI」的正向循環,理論上可能導向爆炸式成長。它的特色是「無歷史可循」,可能急速起飛、也可能很快熄火。所需資源是高階 AI 算力,加上實體實驗與製造的時間(最為關鍵)。
- 路徑四:多Agent集體(Multi-agent Collective)。 這條我認為最特別,就算單一模型停在AGI、不再變聰明,只要把它複製成大量實例、組成協作的集體(如自動化公司、agent 市場),整體仍可能展現超人的能力。它呼應了第二節那個伏筆,「掌握程式碼」讓無損複製成為可能。所需資源是大量的推論算力、互連頻寬與記憶體。
在這四條路徑中,與台灣直接相關的是第一與第四條,兩條路徑雖方向相反、卻同樣指向台灣的強項。路徑一的Scaling是台灣的「燃料供應鏈」主場。當模型與訓練持續放大,需求會集中在三個台灣具壓倒性地位的環節:先進製程(晶圓代工)、先進封裝(CoWoS、CoPoS、FOPLP),以及高頻寬記憶體(HBM)的封裝與測試。這條路徑只要還在跑,台灣就是它的燃料管線。這也是過去三年台灣 AI供應鏈受益的主邏輯。路徑四的多 Agent集體則把台灣的價值,持續性的從「訓練」延伸到「推論與互連」。 跑一百萬個協作的 agent,吃的不是訓練算力,而是推論算力、節點間的互連、以及搬移資料的記憶體頻寬。這把價值推向 scale-up 互連網路、光互連(CPO/共封裝光學),以及解記憶體牆的各種封裝技術。這些同樣是台灣供應鏈深度卡位的領域。換句話說,無論 AI 的重心是在「把模型練大」還是「讓海量 agent 協作」,台灣都在必經之路上,只是受惠的環節從訓練側挪向推論側。至於路徑二的典範轉移,我認為對台灣是雙面的,神經形態或類比運算若成真,可能重寫「什麼硬體有價值」,是現行 GPU 典範的尾部風險;路徑三的遞迴改進則有一支「AI 設計晶片」直接利多 EDA 與製造流程優化。但這兩條都還在很早的階段,目前是主題、不是標的。
圖三、從 AGI 到 ASI 的四條路徑

Source: 智璞產業趨勢研究所繪製
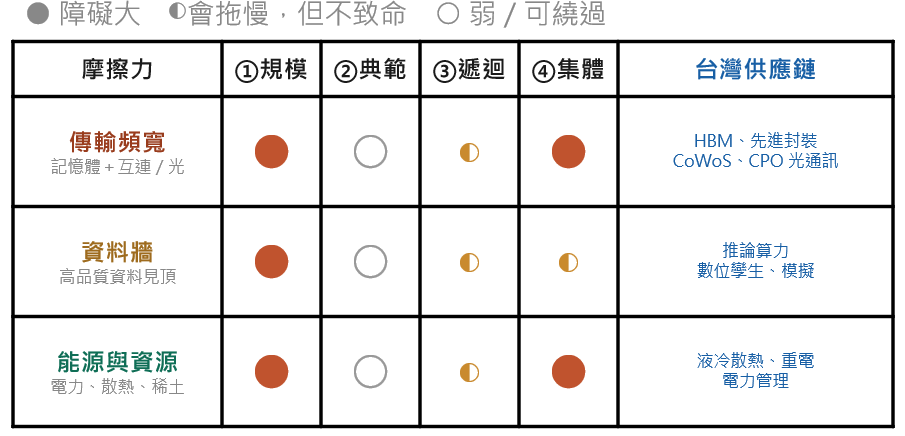
報告列了六項潛在瓶頸,並坦言無法判斷它們究竟是「拖慢的摩擦」還是「停滯的阻礙」,Google DeepMind應該也同意這本身就是開放問題。因此這裡只挑與台灣產業最相關的三項。
- 資料傳輸頻寬的瓶頸,也是最重要的。報告明白指出:即使經濟資源與原始算力都能繼續擴張,現行硬體架構的物理限制仍可能成為瓶頸。具體而言,當模型變大,效能的關鍵不再只是「算得多快」,而是「資料搬得多快」,而這包含兩個層面:一是記憶體與運算單元之間的資料搬移(memory bandwidth limits),二是成千上萬顆晶片彼此之間的高速通訊(interconnect bottlenecks)。報告直言,這兩者都會逐漸主導整體效能、導致 scaling 報酬遞減,「除非發展出新的硬體典範或互連技術」。這句話幾乎是替台灣的相關供應鏈量身背書(這是我個人觀點,非GOOGLE 意向)。記憶體側的瓶頸,指向 HBM(高頻寬記憶體)與先進封裝(CoWoS 等)以及已經發生的排擠效應;晶片與節點間的通訊瓶頸,則指向高速互連、scale-up 網路,乃至光通訊與傳輸設備與製造技術的升級(插拔 800G→1.6T→3.2T;CPO光通訊等)。換言之,報告等於用它自己的語言確認:運算的瓶頸正從「運算」本身,轉向「資料的傳輸」,而無論是記憶體還是光通訊,這條「傳輸頻寬」的戰線,正是台灣供應鏈最深度卡位的核心戰場。
- 資料牆,模型規模的成長,已經超過全球新增高品質資料的速度。報告認為這是「摩擦、而非根本阻礙」,因為對策(合成資料、模擬、RL 環境、agent 試誤)幾乎全都能用算力來換。這也呼應前面所說的「RL 環境」趨勢。對台灣的含意是:資料必然不夠,可能的解法就是「用算力造資料」,而造資料本身就是大規模的運算與推論需求;再加上終端應用情境的資料生成,例如數位孿生(digital twin)對工廠、城市、設備的模擬——資料牆不但不會削弱算力需求,反而把它導向另一個出口。
- 能源與資源,這是最實體、也最難用技術繞過的一項。算力的盡頭是電力,資料中心的擴張,最終受限於電網、土地、散熱與稀土。這一點,黃仁勳在 COMPUTEX 2026 把 AI 基礎建設比喻為「五層蛋糕」,而最底層、作為一切算力第一基礎的,正是能源,「AI 即時生成智慧,需要即時生產的電力」。他甚至點名,AI工廠需要的不只是博士,還有電工、水管工、鋼鐵工、安裝與操作人員。換言之,當業界還在比拼晶片規格時,真正可能限制 AI 天花板的,反而是後端能否穩定、有效率地支撐高功耗運算。
表二、四條路徑 × 三項摩擦力 × 台灣供應鏈
Source: 智璞產業趨勢研究所繪製
- 結論
最後,我認為這份報告不是要告訴我們「AGI、ASI 何時到來」。而是把一個被浪潮模糊的事實重新講清楚。而在滿是不確定的圖景中,有一件事是確定的:無論 AI 走哪一條路徑、被哪一項摩擦力拖慢,Google DeepMind認為算力都會持續是稀缺資源,改變的只是它被花在訓練、推論,還是製造資料。而支撐這一切的底層,是先進製程、先進封裝、傳輸頻寬(記憶體與光通訊)、散熱與電力,這幾乎條條通向台灣。換句話說,這份報告對台灣最重要的啟示無關乎 AGI 的時程:不管這條路最終走多遠、走多快,台灣都站在它的必經之處。能力的天花板或許還看不清,但通往天花板的每一階,都得從台灣的供應鏈上踏過去。
延伸閱讀
 六月_玻璃基板專題|玻璃基板之技術與供應鏈分析
六月_玻璃基板專題|玻璃基板之技術與供應鏈分析





