
五月_AI 光通訊專題|AI資料中心高速互連下CPO的定位 -CPO取代場景、技術演進與PCBA角色轉移
作者:智璞產業趨勢研究所執行副總 林偉智
AI運算競賽已從「GPU 運算力軍備競賽」進入「互連頻寬軍備競賽」。如果 GPU是大腦,光模組就是神經系統。單一 AI 訓練叢集規模已從千卡擴大至萬卡、十萬卡等級,nVIDIA Rubin Ultra 規劃 288-die rack,單 rack 功耗高達 450-500kW。在這樣的規模下,傳統銅線的物理極限將成為最嚴峻的瓶頸:112G/lane 銅線最遠約7公尺,到 224G/lane 僅剩約2.5公尺,且當SerDes 速率演進至 448G 時幾乎無法在銅線上使用。與此同時,功耗問題同樣迫切,nVIDIA 指出,25 萬顆 GPU 叢集中光模組消耗 45MW,100 萬顆 GPU 時達 180MW,光模組約占叢集總功耗 30%。這些的限制逐漸畫出AI資料中心的傳輸邊界。
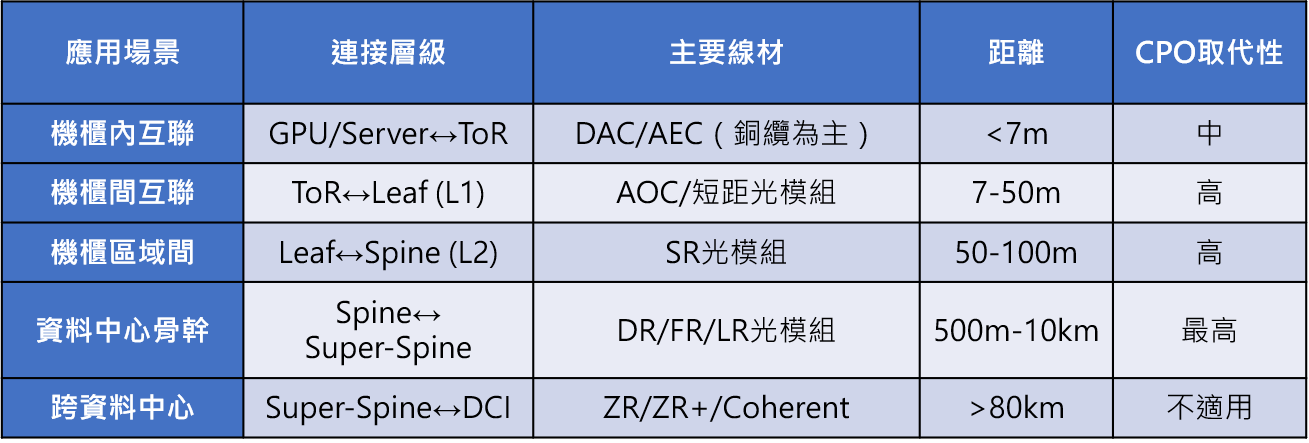
資料中心網路主流採胖樹架構(Fat-tree),分為 L1/L2/L3 三層,不同層級使用不同的連接線材。在機櫃內(<7m),GPU/Server 至 ToR(Top of Rack) 交換器之間主要使用 DAC(Direct Attach Copper,無源銅纜)、ACC(Active Copper Cable,有源銅纜)、AEC(Active Electrical Cable,有源電纜)等,其中銅纜方案,以及 AOC(Active Optical Cable,有源光纜);機櫃間互聯(7-50m)以 AOC 或搭配 DSP 的短距光模組為主;機櫃區域間(50-100m)使用 SR 光模組;資料中心骨幹(500m-10km)使用 DR/FR/LR 光模組;跨資料中心(>80km)則使用 ZR/ZR+/Coherent 方案。
市場規模方面,在高速線材市場方面,根據 LightCounting 與 Credo 資料,2026 年全球高速線材市場預估達 41.1 億美元,年增 39%,主要由 800G 與 1.6T 規格的升級需求所驅動。其中銅纜方案在短距離仍具成本優勢,但隨 SerDes 速率持續提升,光纜與光模組的佔比正在快速擴大。而CPO 整體解決方案市場(涵蓋光引擎、外部雷射光源、FAU、Fiber Shuffle、封裝等元件)仍處於萌芽階段,但成長斜率極為陡峭。根據 IDTechEx 預估,2026 年市場規模約 1.2 億美元,2030 年達 80 億美元,2036 年突破 200 億美元,2026-2036 年 CAGR 約 66.8%。從終端設備來看,LightCounting 預估 CPO 交換機出貨台數將從 2025 年的 14.3 萬台,到2026年的 20萬台,預估至 2028 年的 229.8 萬台,三年 CAGR 達 100.2%。
CPO主要取代場景與原因
CPO(Co-Packaged Optics,共同封裝光學)將光學引擎直接與交換器 ASIC 共同封裝在同一載板上,把光電轉換距離從傳統可插拔模組的 15-30 公分縮短至毫米級。它主要取代的是「可插拔光收發模組」在高速交換器中的角色。他能解決:
- 功耗瓶頸:DSP 約占可插拔模組功耗 50%(10-14W),當 SerDes 速率推進到 400G/lane(3.2T 世代)時,單模組功耗估計達 40-60W,已超出 OSFP-XD 的 40W 散熱上限。
- 訊號完整性:可插拔模組距離 ASIC 的 15-30cm PCB 走線造成嚴重訊號衰減,CPO 將此縮短至毫米級,nVIDIA 官方數據顯示訊號完整性提升 63 倍、插入損耗從 22dB 降至 4dB。
- 頻寬密度:CPO 可在更小空間實現更高頻寬,例如 NVIDIA SN6800 以 5U 空間實現 409.6T 交換容量。
表一、資料中心網路架構與CPO取代性分析
source. LightCounting、Credo、智璞產業趨勢研究所整理
CPO 取代的急迫性,骨幹層最高、機櫃內反而最低。資料中心骨幹(Spine ↔ Super-Spine)的交換器端口數量最多、每個端口都是光模組、功耗最集中,CPO 的功耗與密度優勢在此場景效益最大,nVIDIA Spectrum-X(409.6T)與 Broadcom Davisson(102.4T)都是定位於骨幹級的 Scale-out 交換器,也是 CPO 最先導入的產品。機櫃間互聯(L1/L2)同樣受益於 CPO 的訊號完整性優勢。相反地,機櫃內 Scale-up 互連(GPU ↔ NVSwitch)目前對 CPO 的需求反而不急迫。以 nVIDIA NVL72 GB300為例,機櫃內 GPU 與 NVSwitch 之間透過 NVLink 協議以銅纜 DAC 連接,共 5184 條、每條 200G。nVIDIA 的策略是以大量通道數堆疊總頻寬(5,184條 × 200G=約 518T),而非追求單通道 400G/lane 的極限速率,因此銅纜在此場景仍然夠用。即使到下一代 Rubin NVL144,Scale-up 仍使用銅纜(可能改為以大型 PCB 中板取代逐條銅纜佈線,簡化機櫃內連接架構,PCB all to all connection)。直到 Rubin Ultra NVL576(8 機櫃架構),跨機架的 L2 Scale-up 才首度引入光學互連(5,184 條光纖 × 400G,搭配 324 顆 3.2T 光引擎),預計採用的是 VCSEL NPO。真正在 Scale-up 中導入 CPO 要等到 2028 年的 Feynman 平台(NVLink-8)。
Credo 推出的 ACL 線材可將銅纜延伸至 20-30m,但無法解決 400G/lane 以上的功耗問題。越往長距離(L2/L3/DCI),原本就已經使用獨立光模組,CPO 在這些場景的直接取代性反而較低。值得注意的是,1.6T 世代仍以可插拔模組搭配 LPO 為主流。目前業界調查Broadcom TH6 雖有 CPO 版本,但目前雲端廠幾乎都採用純電版本,CPO 版尚未大量導入。2026 年實際量產出貨的 CPO 交換器以 nVIDIA Quantum-X為主。此外,業界也需區分 CPO 與 NPO(Near-Packaged Optics,近封裝光學)的差異:CPO 是將光引擎放入 ASIC 封裝內部,與晶片共封裝於同一基板上(距離數毫米);NPO 則是將光引擎放在 PCB 板上靠近 ASIC 的位置(距離數公分),未進入封裝內部。NPO 的優勢在於可在板級更換維修、不需改動 ASIC 封裝設計,且以 VCSEL 多模光纖實現(約1pJ/bit)的極低能耗,部署門檻較 CPO 低。Broadcom 即同時布局矽光子 CPO(單模、長距)與 VCSEL NPO(多模、短距 <50m)雙軌路線。整體而言,真正的分水嶺在 400G/lane(對應 3.2T 世代),預估約 2028-2030 年 CPO 才會大量採用,在此之前 Pluggable、LPO、NPO、CPO 多種架構將長期並存。
機櫃內高速線材與CPO市場概況
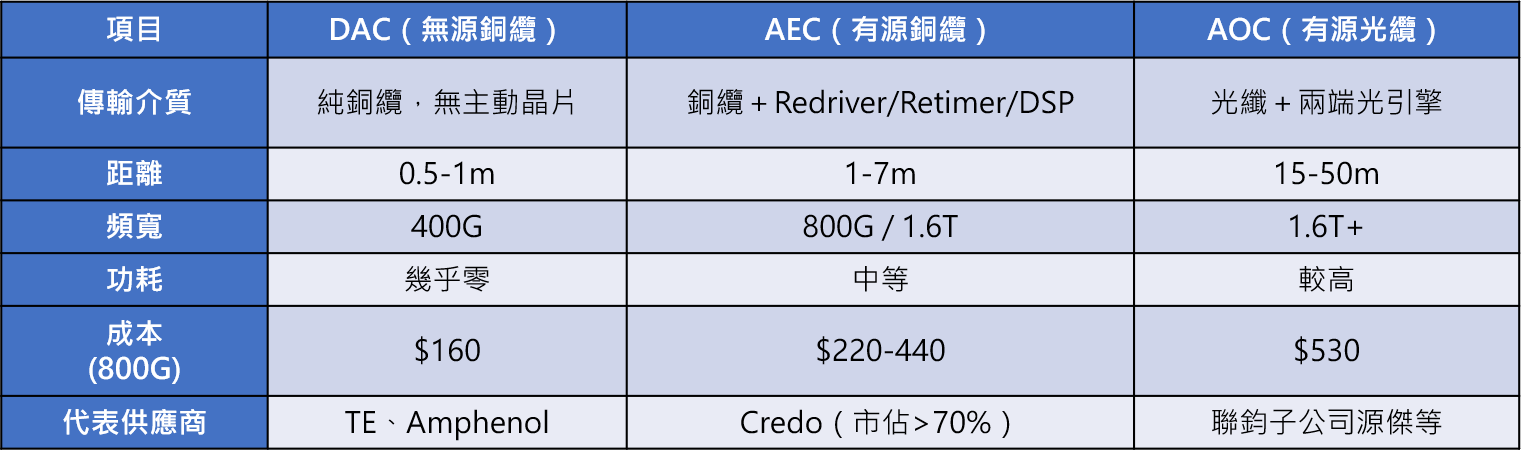
雖然 CPO 的最高取代急迫性落在資料中心骨幹的 Scale-out 交換器,但在 CPO 全面放量之前(預估 2028-2030),機櫃內互聯仍是目前高速線材需求最密集、成長最快的場景,這也是 CPO 到來前的過渡主流市場。GPU/Server 至 ToR 交換器之間的短距離連接主要由 DAC、AEC、AOC三種方案競爭。三者的核心差異在於「是否內建主動晶片」與「傳輸介質」,這決定了各自的距離、功耗與成本。理解這些短距方案的現狀與極限,也有助於釐清 CPO 未來在不同場景的切入時機。從市場規模來看,銅纜傳輸市場(DAC + AEC 合計)受惠於 AI 叢集 Scale-up 需求,正以 CAGR 26.7% 快速成長,2026 年預估約 4.65 億美元,2027 年約 6.9 億美元。其中 AEC 成長最為強勁,龍頭 Credo 的 FY2026 Q3 單季營收達 4.07 億美元(年增 201%),主要客戶涵蓋 Amazon、Microsoft、xAI 等超大規模業者,每座 GB300 機櫃預估使用約 90 條 AEC。2026/2027 年 AEC 主流規格將分別從 800G 升級至 1.6T,帶動單價與用量同步提升。不過,隨著 SerDes 速率從 112G 推進到 224G 再到 448G,銅纜可用距離急劇縮短(112G 約 7m、224G 約 2.5m、448G 幾乎無法使用)。這意味著銅纜方案的高成長窗口可能集中在 2026-2028 年,之後將逐步被光學方案(包含 NPO 與 CPO)侵蝕。
表二、機櫃內三種高速線材規格比較
source. Credo、LightCounting;智璞產業趨勢研究所整理
CPO光學引擎由六大核心元件組成。PIC(光子積體電路)承載所有光學功能,包含光波導、調變器(MZM/MRM)與光偵測器(Ge PD),設計由 Broadcom、nVIDIA、Marvell 等自行完成,製造集中於台積電 COUPE、GlobalFoundries Fotonix、Tower Semi 三大矽光子代工平台。EIC(電子積體電路)驅動 PIC 運作,包含雷射驅動器(Driver)、跨阻放大器(TIA)與加熱控制器。其中高速數位訊號處理部分採用先進 CMOS 製程(5nm/3nm),但類比前端電路(Driver、TIA)對線性度與雜訊特性的要求更高,不一定採用最先進節點。EIC 通常由 PIC 設計商一併設計,透過台積電 COUPE 平台以 SoIC-X 3D 堆疊方式整合於 PIC 之上。ELS(外部雷射光源)因雷射對溫度極度敏感(MRM 諧振波長隨溫度漂移,且與高瓦數 ASIC 共封裝會產生熱飄移),因此採取將雷射光源獨立於主封裝體之外的設計,透過光纖將連續波光訊號導入光學引擎。目前 Lumentum 為 nVIDIA CPO 交換器的主要 CW 雷射供應商(已投資 Lumentum 20 億美元+多年期採購承諾),nVIDIA 同時也與 Coherent(投資 20 億美元)及 Ayar Labs(投資 5 億美元)建立策略合作,佈局多元光源供應鏈。FAU(光纖陣列單元)負責微米級光波導與外部光纖的精準對接,是良率最敏感的環節。Fiber Shuffle 負責將光學引擎端的高密度光纖陣列重新排列至標準面板連接器位置。以51.2T CPO 交換器為例,內部約需 1,152 條光纖(含 1,024 條資料光纖與 128 條偏振維持光纖),102.4T 則倍增至約 2,000 條以上,在交換器有限的空間內管理如此大量的光纖佈線,製造複雜度極高。
在 CPO 交換器領域,Broadcom 是最早量產的廠商,TH5-Bailly(51.2T)2024 年即交付客戶並通過 Meta 百萬埠小時零中斷驗證,nVIDIA方面,Quantum-X(InfiniBand)已於 2026 年初商用供貨,Spectrum-X(Ethernet)預計 2027 年才會較具規模地出貨。兩家均採用台積電 COUPE 平台,但光學架構不同:nVIDIA 採 MRM(微環調變器),Broadcom 採 MZM(馬赫-曾德調變器)。
關鍵轉折應會在 2028 年 Feynman 平台:NVLink-8 首度引入 CPO,代表 CPO 從 Scale-out 演進至 Scale-up 場景。凱基投顧推估 2027 年光引擎需求約 3,000 萬顆,2028 年 Scale-up 導入後將成長至 6,000 萬顆以上。
可插拔 / LPO / CPO 的差別與散熱極限
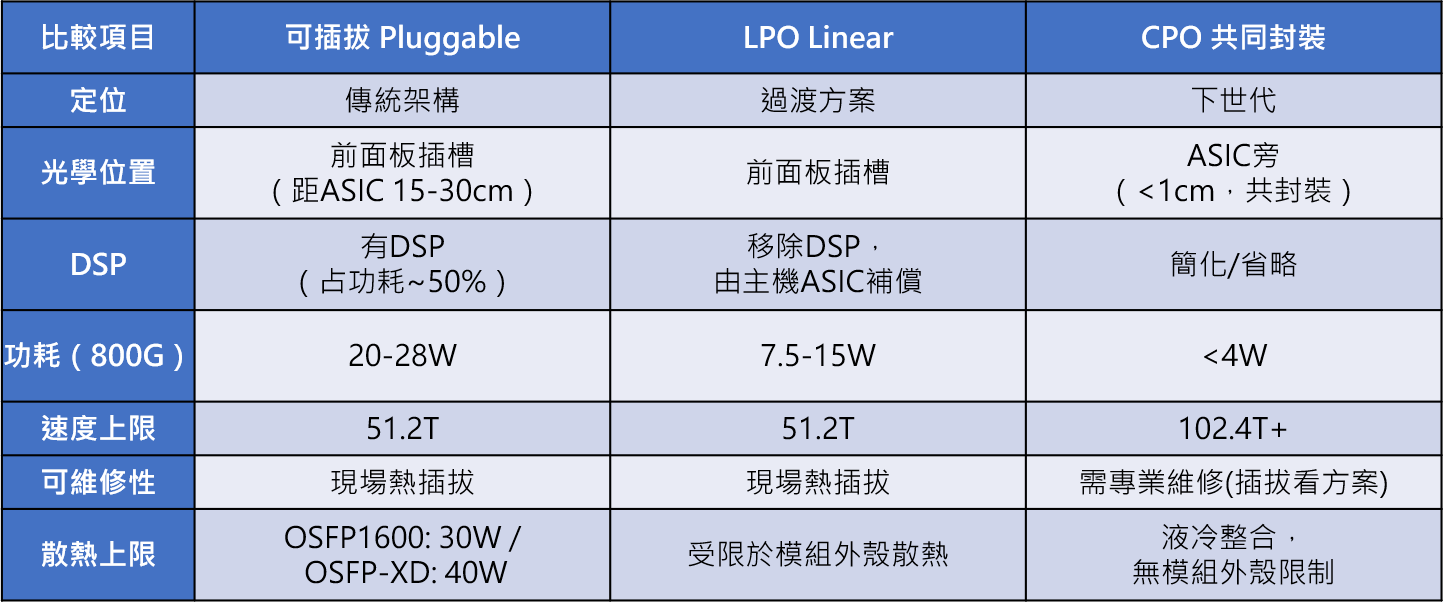
散熱極限是推動架構演進的關鍵之一。在可插拔模組中,DSP/SerDes 佔功耗約 50%(10-14W),雷射驅動器/調變器約 20%(4-6W),接收器約 12%(2-3W),電源管理約 10%(2-3W),合計約 20-28W。OSFP1600 散熱上限為 30W,OSFP-XD 為 40W。另外LPO(Linear Pluggable Optics)透過移除模組內的完整DSP,保留線性類比前端,將訊號補償交由主機 ASIC/SerDes 處理,可降低 30-50% 模組功耗。LPO 是當前 800G/1.6T 世代的一個重要方案,在維持可插拔可維修性的同時延長了該架構的壽命。然而當 SerDes 推進至 400G/lane 時,即使採用 LPO,模組功耗仍估計達 40-60W,超出 OSFP-XD 散熱上限。這正是 CPO 從「可選方案」轉為「規模化必要條件」的分水嶺。
表三、三大光模組架構規格比較
source. OSFP MSA、Broadcom、智璞產業趨勢研究所整理
CPO 將光學引擎直接整合至 ASIC 同一基板,傳輸距離從公分縮至毫米,消除 DSP 需求,功耗可降低 65-73%。此外,CPO 採用液冷設計,突破了可插拔模組外殼的散熱天花板,理論上沒有功耗上限的結構性限制。800G 為當前 AI 資料中心主流規格(2026 年占高速線材市佔 43%),1.6T 預計2027年開始大規模出貨。速率演進路徑為:
400G(4×100G/lane,採 PAM4 調變,2020-2023 成熟量產)→
800G(8×100G/lane,PAM4,2023-2025 主流放量)→
1.6T(8×200G/lane,PAM4,單通道速率首度翻倍,2027 量產起步)→
3.2T(8 通道×400G/lane,PAM4,SerDes 速率再翻倍至 224Gbps,開發中預計2028)。
每一代速率提升的核心手段是拉高單通道速率,而非增加通道數,這也是功耗與散熱壓力隨世代指數上升的根本原因。真正的分水嶺在 400G/lane(3.2T 世代),屆時 CPO 將從「可選」轉為「必要」。
PCBA的角色轉移,從承載模組到整合封裝載體
目前,整個光通產業處於本益比極高,以剛公布光通訊雷射大廠Lumentum (LITE)第一季的財報來看,營收$8.1億年增90%、EPS $2.37均優於市場共識,毛利率及營益率大幅擴張,營收指引中位數$9.85億更遠超華爾街預期,整體表現亮眼,但股價過去一年已漲逾15倍,市場對其標準極為嚴苛,盤後仍下跌逾 5%。這反映的是整個光通訊供應鏈,上從InP基板、EPI、雷射模組、矽光、FAU等的成長預期都已被充分定價,估值上行空間日趨有限。與此同時,OFC 2026 上 Arista 主導的 XPO(eXtra dense Pluggable Optics)MSA 正式亮相,為可插拔模組爭取了更長的生命週期。傳統插拔架構在未來三年仍是主流大宗,在此背景下,值得探討的是:傳統插拔架構下的 PCBA 封裝,可能的路徑演進為何?
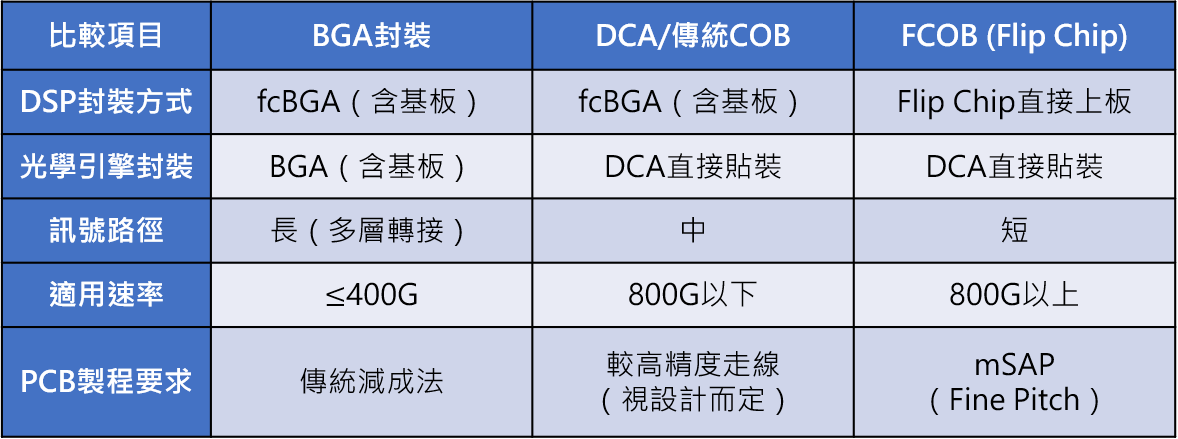
隨著光收發模組速率從 400G 推進到 800G、1.6T 以及未來CPO架構放量導入,PCBA 上的封裝方式面臨根本性轉變。在傳統可插拔模組中,封裝方式經歷了三個階段的演進:
- 第一階段(fcBGA):DSP 以 Flip Chip 方式焊接到基板上(Substrate),再以 BGA 錫球連接到 PCB;光學引擎(PIC + Tx/Rx IC)同樣經基板轉接至 PCB。此架構經過兩層轉接,轉換節點最多、訊號路徑最長,在 800G以上速率下訊號衰減嚴重,已不適用。
- 第二階段(DCA/傳統 COB):光學引擎改為 DCA(Direct Chip Attach),晶粒直接貼裝到 PCB 上,省去一層基板,縮短訊號路徑。但 DSP 仍維持 fcBGA 封裝(經基板轉接),為過渡方案。
- 第三階段(FCOB / Flip Chip on Board):DSP 晶粒也改為 Flip Chip 直接焊接到 PCB 上,省去所有中間基板,所有晶片以最短路徑連接,訊號衰減最小。這是 1.6T 以上規格的標準封裝方式。FCOB 對 PCB 基板的線寬線距要求極高,需採用 mSAP(Modified Semi-Additive Process,改良型半加成法)製程,才能實現 Flip Chip 微凸塊所需的極細間距焊墊與走線佈局。mSAP 過去主要應用於智慧型手機 HDI 板,如今隨著封裝從 fcBGA 演進到 FCOB,正從消費電子跨入高速光通訊領域,成為 1.6T 以上光模組 PCBA 的關鍵製程能力。Flip Chip 相較傳統 COB 在產量上可達近 5 倍效率。
表三、光收發模組PCBA封裝方式演進
source. Cisco、SemiAnalysis、智璞產業趨勢研究所整理
而在CPO架構下,PCBA應不再只限於PCB上。當光學引擎從可插拔模組移入 ASIC 封裝內部,傳統 PCBA 的角色必然出現根本性位移。在 CPO 架構下,光引擎需與交換器ASIC共同封裝於 CoWoS 或有機基板上,PCBA 從「承載獨立可插拔模組的主板」轉變為「整合光學引擎與 ASIC 的高密度封裝載體」。這可能帶來幾個重要的角色轉移方向
- ABF 載板需求升級:CPO封裝體的載板面積顯著增大。以 nVIDIA Spectrum-X 為例,單顆 ASIC 需搭配32顆光引擎,整體封裝面積遠大於傳統交換器。欣興電子等 ABF 載板供應商直接受益,根據 Latitude Design Systems 的分析,ABF 載板供需缺口預估 2027 年達 21%,T-Glass 短缺推漲價格 20-30%。
- CoWoS/SoIC 先進封裝取代部分PCBA功能:台積電的 COUPE 平台採用 SoIC-X 銅-銅混合鍵合技術,將 EIC 垂直堆疊於 PIC 之上,整合約 2.2 億電晶體與約 1,000 個光學元件。COUPE 分三代演進:Gen 1(2026)用於 OSFP 連接器的光引擎 1.6Tbps;Gen 2(2027-28)為 CoWoS 封裝 CPO 6.4Tbps 主機板級整合;Gen 3(2029+)全整合至處理器/交換器封裝。這意味著原本由 PCBA 承擔的電光轉換功能,逐步被先進封裝技術吸收。
- Chip-on-Board(COB)技術在 ELS 組裝中的新角色:CPO 架構中,外部雷射光源(ELS)需要以 Chip-on-Board 方式進行組裝,將雷射晶粒直接打線或覆晶至 PCB 基板上。這是 COB 技術在 CPO 生態中延續其價值的重要路徑。Broadcom 陣營的 ELS 即採用 COB 技術進行組裝。
- XPO架構帶來的PCBA新需求:Arista主導的 XPO(eXtra dense Pluggable Optics)方案,將8根光引擎放在同一PCB上,保留可插拔特性但密度提升4倍(單模組 12.8T),並整合液冷散熱板。XPO對PCB 提出了新的高密度封裝要求:更多層數、更高的訊號完整性設計、以及與液冷系統的整合能力。這意味著即使在非CPO路線中,PCBA 的技術規格也在快速升級。
- 光電元件貼合與對準(Optical Alignment)為PCBA的自然延伸方向:CPO 光學引擎的組裝過程中,外部雷射光源(ELS)的晶粒貼合、FAU 與 PIC 的光學對準、以及封裝後的底填點膠,本質上都是「高精度對位+貼合+接合」製程,與 PCBA 廠既有的 Flip Chip placement、Underfill dispense 等核心能力同源。差異在於精度等級從傳統 SMT 的 ±25μm 提升至光學對準所需的次微米級,需要投資六軸對位平台與主動對準設備。相較於跨入 CoWoS 先進封裝或 ABF 載板製造,光電貼合是 PCBA 業者更務實的能力延伸路徑。
總結而言,CPO 時代的 PCBA 不再只是傳統的「印刷電路板組裝」。對 PCBA 業者來說,向上跨入 CoWoS 先進封裝或 ABF 載板製造並不切實際,但沿著既有的精密貼合能力向光電領域延伸,從 Flip Chip 封裝、mSAP 細線路製程、到光學元件的對準與貼合,才是最務實的轉型路徑。掌握高良率 Flip Chip 製程的 PCBA 廠商近三年仍將在可插拔模組中受益於 1.6T 升級,中長期則需布局 ELS 晶粒貼合、FAU 光學對準等 CPO 組裝環節,才能在產業價值鏈重新分配的過程中站穩位置。
最後,CPO 正從實驗室走向規模化量產,2026 年是驗證放量的關鍵年,2027-2028 年才是真正的光通元年。短期應關注 Scale-out 交換器中光引擎的量產進度與良率爬坡,中期需追蹤 CPO 從 Scale-out 延伸至 Scale-up 的時間點。這將決定光引擎需求量的爆發斜率。PCBA 的角色轉移是另一條被市場低估的主軸。從 BGA 到 Flip Chip 的封裝演進提升了訊號完整性,但更深層的變化在於:CPO 將原本 PCBA 承擔的光電轉換功能推向先進封裝與系統整合,傳統 PCBA 的定義正在被重新書寫。未來的贏家不一定是做最多 PCB 的廠商,而是能在載板、先進封裝、光纖管理、液冷整合等新領域建立能力的參與者。光通訊正從 AI 基礎設施的配角轉變為核心戰略層。Pluggable、LPO、CPO 三種架構將在未來數年並存,但 CPO 在高速、高密度、低功耗的極致追求下,終將成為 AI 超大規模叢集的標準配備。








