
AI晶片專題|百家爭鳴的邊緣之AI推論晶片趨勢解析(上)
Author: Mr. Lin Weizhi, Executive Vice President, Ji-Pu Industrial Trend Research Institute
As mentioned earlier, if AI agents are to be popularized on a large scale in the future, it is not enough to rely on "large-scale models" alone, and it is necessary to integrate computing capabilities at different levels, such as the cloud, edge, and endpoints, etc. Once LLMs are uploaded to the network, the cost of inference often exceeds the cost of training, and the scale of inference in a single day may be as high as hundreds of millions of tokens, and the computational efficiency and power consumption of chips will be magnified and examined at that time. Taking NVIDIA's Blackwell as an example, it is claimed that it can reduce the energy consumption and OPEX of LLM inference by 25 times, which highlights the importance of specialized hardware (e.g., GPUs, ASICs) in the inference scenario. In addition, cloud inference requires milliseconds of response latency, while edge devices are challenged by power consumption and thermal constraints. In summary, I believe that the two most critical challenges in today's inference technology are as follows, and will be the deciding factors in the competition for inference chips:
Challenge1: Throughput(Throughput) and Data Delay(Latency)balance optimization
Challenge2: Prefill(Prefill)Stage and decode(Decode)Stage specialization
Throughput in the first point refers to the effective amount of work a system can accomplish in a single hour, reflecting the combined performance of hardware computing power, memory bandwidth, and software scheduling. Higher throughput means that the system can serve more users or accomplish more tasks in the same amount of time.
第二點的預填(Prefill)階段,指的是模型在前處理階段(第一次輸入)一次性計算整段輸入語句(Prompt / Context),並產出所有注意力所需的 Key/Value 向量(KV-cache);而解碼(Decode)階段,則是模型進入逐字(Token-by-token)生成階段,每生成一個新 token,即重用預填好的K/V向量,重新執行注意力運算,直到句子結束。由於這兩個階段對硬體資源的要求完全不同,Prefill主要是吃算力、而Decode吃頻寬。目前業界傾向將其部署在不同類型的專用運算硬體上,例如:Prefill由算力充沛的 GPU 負責,而Decode則交由具備大容量 SRAM 的低功耗 ASIC 執行,並透過高速互連將 KV-cache 無縫傳遞,以實現性能最大化與能效最優化。從系統架構與工程實作的角度來看,這兩項挑戰雖高度相關,但本質上屬於不同層次。其中「挑戰1」著重於整體系統層級的宏觀效能取捨,尤其是在多用戶、大規模推論時的資源分配與延遲控制;「挑戰2」則偏重於推論階段的計算操作差異與專業化策略。儘管挑戰2是提升效能的基礎,但要真正改善使用者體驗,仍需透過完整的調度(scheduling)、記憶體管理(cache management)、以及高效批次處理策略等才能達成,因此這兩個挑戰成為當前晶片大廠主要解決或取捨的問題。目前AI模型主要仰賴nVIDIA的GPU進行訓練,但該公司產品售價偏高且供貨條件嚴苛,促使Google、AWAS、Microsoft、Meta等大型AI CSP企業開發多款適用自家AI模型的ASIC晶片,不只想在未來能降低nVIDIA的GPU依賴,也想在訓練晶片市場殺出一條血路。以下就來解析這四大CSP企業與nVIDIA如何在這議題上搶占先機。
說Google是在AI上耕耘最久的CSP企業一點也不為過, 2015 年 Google Brain 成立 TPU 專案,2016 年釋出 TPU v1 以 INT8 推論為主,開啟CSP企業自研AI晶片先河。可能是發現要降低對nVIDIA依賴有一定難度又或者是仍在試探自研晶片的定位,因此v2–v5逐步兼顧訓練與推論,如下表1。2024年推出TPU v6e(Trillium)單晶片 HBM 升至 96 GB、頻寬 1.64 TB/s,整體效能比 v5e大約有67 %的進步,正式切入 100 B 級 LLM 推論服務;2025年再推出 TPU v7「Ironwood」,首次明確標註推論專用(Inference-only)。大容量 KV-SRAM (150 MB)+ 7 TB/s HBM,專為長的上下文與多用戶推論而打造;ICI 1.2 TB/s(Inter‑Chip Interconnect,晶片互連) + Hex-LLM(新一代LLM 軟體架構,會即時檢測每條請求的 Prefill與 Decode進度,再把工作動態派給對應 TPU),將 Prefill/Decode 拆分為不同分片並行,結合9216-chip Pod(576 個16-chip Cube)架構,使其維持雲端高的每秒查詢數(Queries Per Second, QPS)以及末端延遲需求P99 < 1秒(在延遲分佈中,99% 的請求在延遲達到指定時間內完成,而剩下的1% 的請求則延遲超過了這個時間,稱P99末端延遲)。Google 的TPU 世代演進已從「兼顧訓練+推論」可能轉向「高能效推論專用晶片 + 大規模低延遲互連」;Ironwood 的推出確立 Google 在自家雲端推論堆疊的技術路線,並透過 ICI 與 Hex-LLM 把 吞吐-延遲權衡 與 Prefill/Decode 專門化等兩大挑戰一次整合進硬體與軟體中。目前只能在 Google Cloud用,但打包成「Hyper computer」服務,上線就能跑,其客戶不用自己買AI Server。Google的TPU 推出到第七代,並決定將「推論和訓練分手」;Ironwood 就是專門替低延遲、高流量的大模型服務而生的武器。雖然只在 Google Cloud (Hyper computer) 內使用,卻仍有兩股穩定需求來源,一是Google 自家產品如Search、YouTube、Ads、Gemini 等AI 晶片的需求,另一個是雲端外部客戶,如OpenAI、遊戲、企業RAG(Retrieval‑Augmented Generation, 檢索增強式生成)導入產品或內部系統時,對AI算力需求增高後的租賃需求,同時也會提升其TPU的需求。目前觀察此方向應該不會讓Google的 TPU像 nVIDIA GPU 那麼廣泛使用,但總量也不會小且可以持續疊代,可能會有推估數十萬片/年等級(取決於 GCP 成長 + Google 內部流量),且因為只有 Google 能下單,因此外部景氣波動對產能需求影響相對較小。
表1、Google歷代TPU產品的技術比較
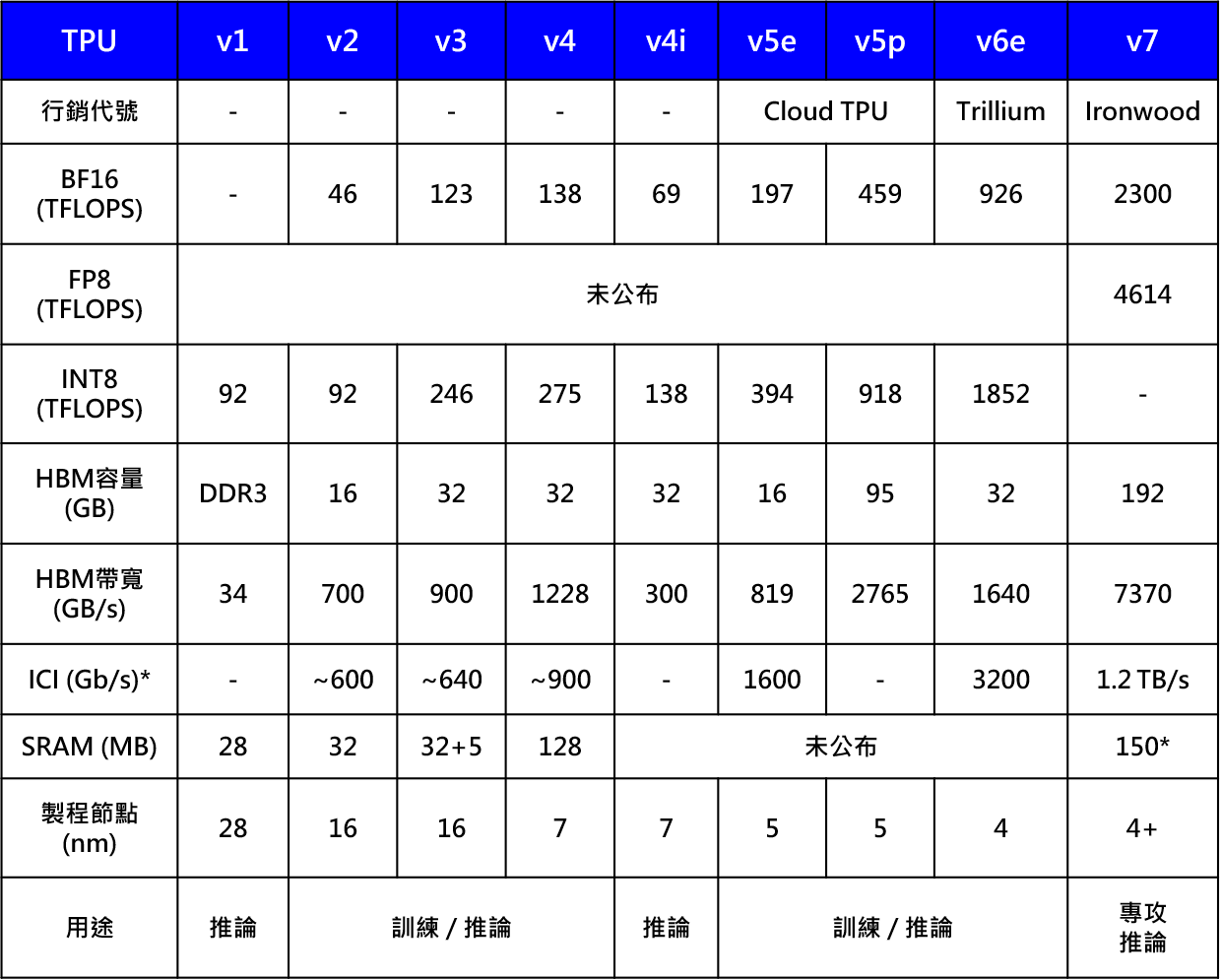
*目前可能往純推論走,但也有資訊顯示內部仍然用其訓練大模型
備註:ICI(Inter-Chip Interconnect),Google 為 TPU 量身打造的晶片間高速互連總線,功能位置大致相當於 NVIDIA 的 NVLink 或正在制定中的 UALink,但僅用於 Google 自家 TPU 叢集。表格中v2~v6之數值為估計值,非官方公布之數字
Source : Google
2018 年,AWS 先以 Graviton(現已至第四代)奠定 ARM 伺服器 CPU 基礎;隔年推出首款 推論 ASIC Inferentia 1,強調高吞吐、低功耗。2020 年 AWS 延續自研路線,發布 Trainium 1,專攻百億參數以上模型訓練;2023 年的 Trainium 2 單晶片算力再提升4x、能效提升2x,已量產佈署於 Amazon Bedrock 與 Anthropic 專用叢集。在推論端,2023年進化到 Inferentia 2,單晶片 FP16達 1 PFLOPS、內建 NeuronLink 192 GB/s 互連;在 EC2 Inf2(AWS 專為大規模 AI 推論打造的加速型執行平台) 實測中對同級 GPU 展現 吞吐 增加4 倍、低末端延遲(P99)進步90 %、$/token 省 40 %。市場雖傳出 AWS 暫停下一代 Inferentia,但 2025 年 AWS 資本支出簡報仍將 Trainium + Inferentia 列為雲端 AI 主力,停更一說尚未獲官方證實,因此我們暫時將其列。整體而言,AWS 形成「Graviton-通用運算 + Trainium-訓練 + Inferentia-推論」的縱深布局,再以 Neuron SDK系統工具集把吞吐-延遲最佳化與 Prefill/Decode 拆分成易用服務。以性價比而言,Inf2 每小時約 0.7 美元,等效吞吐較四張 H100(B200的成本高,因此用H100做對比) 省 35%、推論成本一萬 token 僅 0.004 美元,單片功耗 135 W,電費與冷卻再降 40%,適合追求 <100 ms P99 延遲且必須壓低成本的 SaaS 與新創。為雲端客戶提供相對 GPU 更具成本優勢、延遲更穩定的推論選擇。就「技術侵略性」和「單晶片極限性能」來看,Google TPU v7 (Ironwood) 的確比 AWS Inferentia 2 更激進,AWS 則以降低雲端總體擁有成本(Total Cost of Ownership, TCO)為導向,小步快跑。Google的晶片在延遲、極端吞吐密度上領先,但在每瓦性能、部署彈性與客戶基數上,AWS晶片仍具優勢。我認為主因來自雙方對晶片的策略定位不同,Google 把 TPU 當成內部業務的「極限武器」,AWS 則把 Inferentia 做成雲端客戶的「高 CP 值工具」。
Meta 自 2023 年推出首顆推論專用ASIC MTIA v1以來,核心策略就不是衝單晶片峰值,而是把「每瓦吞吐」壓到極限,以支撐自家臉書動態牆、廣告推薦與中小型 LLM 的龐大即時流量。並不是不在乎「使用者時間」,而是把「在既定功耗下服務最多用戶、同時末端延遲不爆炸」當成首要目標,單晶片峰值放在第二順位讓位給整機房的效率與成本最小化。2024 年發表的 MTIA v2 延續此思路,在相同 90W TDP (Thermal Design Power)下,透過「硬體+軟體」雙向升級,把整機 QPS 再推上一階。在硬體層面(math.) genusMTIA v2把功耗用在刀口上,仍採 8 × 8 小型計算單元(Processing Element, PE) 網格,但新增稀疏運算管線與進階壓縮指令,我自身的理解是,想像一片晶片上放了 8 行 × 8 列共 64 顆PE。每顆 PE 就像一把小算盤,同時各算自己那一小塊資料,64 顆一起動,速度自然比單核快很多。且新增「跳過空位」的專用跑道,也就是在推薦或中小型 LLM 模型裡,大部分矩陣其實充滿 0(稱為稀疏)。v2 加了一條「稀疏運算管線」,專門識別哪些格子是 0,直接跳過不計算;還配合壓縮指令把連續的 0 壓縮起來,搬運量更小,比起v1在常見的推薦(可視為推論)模型與30 B以下 LLM 推論上,速度和效率都大幅提升。晶片上 SRAM 擴大至 256 MB,可將中等規模模型的 KV-cache 直接駐留晶片,並以 128 GB LPDDR5、204 GB/s 頻寬作為外層緩衝,規格為v1的翻倍,即使多用戶同時下指令,資料仍能在一跳內完成搬移。為降低跨 PE 協作延遲,Meta 也將晶片上網路(Network-on-Chip, NoC) 重構為雙向 256-bit Mesh,總帶寬翻倍、端到端延遲減半,避免 Prefill 大矩陣與 Decode 小矩陣在網路層互卡,像是「車道加寬」+「改成雙向匝道」+「邊開邊上貨」,使得 MTIA v2 在同功耗下資料流動更暢通。總頻寬翻倍,任兩顆 PE 之間傳送資料的時間大約減半,直接換成更高吞吐與更低 P99 延遲。軟體層(math.) genusMeta 以 Triton-MTIA 編譯器後端 與 PyTorch 2.0/TorchInductor 深度整合:開發者沿用 Python 前端即可下推到 MTIA,編譯器會自動插入 連續批次 (continuous batching)、張量記憶體重用與動態稀疏調度,把批次大小、算子順序與 SRAM 命中率聯合優化。總結來說,Meta 以 MTIA v2 實現了「功耗可承受、延遲不失控、吞吐極致化」的推論方案,再加上與 PyTorch 原生工作流程無縫接軌的軟體棧,確立了其在內部雲端與邊緣推論中,用 每瓦效率 而非 單卡峰值 取勝的差異化路線。
 News Release|Intel may eliminate 18A process nodes for foundry customers, leaving TSMC virtually unmatched!
News Release|Intel may eliminate 18A process nodes for foundry customers, leaving TSMC virtually unmatched! AI晶片專題|百家爭鳴的邊緣之AI推論晶片趨勢解析(下)
AI晶片專題|百家爭鳴的邊緣之AI推論晶片趨勢解析(下)





