
AI 光通訊專題|2026年OCS在AI資料中心發展趨勢研究(上)
Author: Mr. Lin Weizhi, Executive Vice President, Ji-Pu Industrial Trend Research Institute
2026 年 AI 光通訊的發展方向,可從兩個訊號源觀察:ECOC 2025 歐洲光通信會議,以及年底雷射大廠 Coherent 與 Lumentum 的法說會。隨著生成式 AI 與大規模 GPU 集群爆炸性增長,資料中心網路交換架構正面臨挑戰,傳統光電光(OEO)交換模式已成為限制 AI 效率與規模擴展的關鍵瓶頸。全光交換(Optical Circuit Switching, OCS)作為純光學網路解決方案,正從試驗性部署走向大規模商用。本文為付費月刊內容,以上為公開摘要。
For the first time in the last three years, generative AI has allowed GPUs to grow much faster than the
表一、OEO交換器挑戰與影響

若以目前AI 伺服器擴張架構的趨勢,將會面臨的問題如下:
- Scale-Up (機櫃內/Rack, 1~20 m):這一層主要是 GPU 與 GPU或CPU 之間的直接互連。在ECOC 2025提到在800G(8×100G PAM4)與早期6T(8×200G PAM4)佈建中,100G/lane 的 SerDes 距離已逼近極限,銅纜 reach 多落在1~2公尺範圍。當向 200G/lane 過渡時,reach 會進一步縮短,同時功耗和散熱成為機櫃設計的首要難題。
- Scale-Out (資料中心內, 數十至數百米):這一層跨機櫃、跨 Pod 的 AI 集群佈建。從許多資料顯示,6T與未來3.2T 光模組的 DSP(Digital Signal Processing, 數位訊號處理器)、FEC(Forward Error Correction) 與 SerDes(序列/解序列) 將把功耗推升至不合理的程度,導致傳統主幹枝葉式架構中的Spine層交換機的功耗與延遲問題隨著集群規模的倍數增長而呈指數爆炸。因此巨量頻寬與功耗會是本層的瓶頸所在。
- Scale-Across (跨資料中心, DCI):nVIDIA提出的主要原由是,LLM、MoE、超大型 embedding 模型需要在多資料中心間同步訓練。根據資料指出,全球 Hyperscaler 有超過 95% 的資料中心距離落在 120 公里以內,瓶頸在於動態佈建能力與低延遲。當多個資料中心需協同運作,成為「一個AI集群」時,需要可動態重構佈建的傳輸路徑,以及跨區域的同步低延遲。此處剛好是 ZR(Extended Reach)與 OCS 可共同發揮的距離。
這三個層級各自有不同的物理限制,Scale-Up受到 I/O密度、銅纜物理極限與散熱限制,這些問題本質上屬於封包交換與電介面議題,沒有必要一定要靠光路佈建重構來解決(備註:CPO在能耗與密度上有優勢,但可靠度與維護成本仍需解決)。而另外兩層的瓶頸已經確認無法透過傳統 OEO交換機路徑優化解決。因此OCS被 Hyperscaler 模型推到台前。它並非更快的交換機,而是一種能動態重構光路的佈建、跳過 OEO的光電交換方式,使資料中心不需要再依賴 SerDes、DSP、或多層 spine switch 進行封包交換。特別在Scale-Out和Scale-Across層,OCS能提供動態、低耗、高速率無關的專屬光路,成為解決大規模AI集群網路核心痛點的關鍵技術。OEO與OCS概念如下圖一
圖一. OEO與OCS 交換節點之概念圖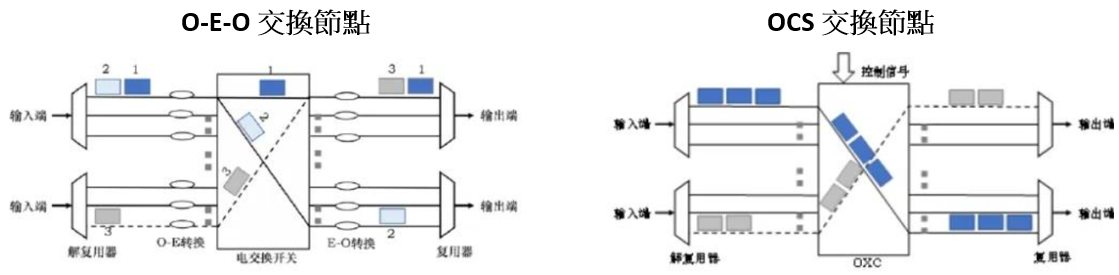
source:東北證券,知乎
什麼是OCS?其運作機制與痛點解決原理
全光交換器(OCS)本質上是一種「光路重構」技術,其核心在於跳過光、電的轉換過程,而非「更快的交換機」或「新型光模組」。其結構定義是一種透過光路直接與光路連接的方式,在交換機內不碰觸電力介面,直接在光域完成連接或轉換的技術。它為每一條連線提供了一條「專屬光路」。透過光學元件(如微機電反射鏡或液晶陣列)直接改變光纖A到光纖B的路徑,不涉及電信號的處理、編碼或解碼,其速率、協議或調變格式皆不重要。
若以路徑來看,傳統OEO交換機為:
光 → 電(SerDes)→ ASIC(封包交換)→ 電(SerDes)→ 光
AI 訓練的數據量極其巨大,當數百 TB/s 的流量要不斷穿越多層交換網路時,這樣的 OEO 過程會產生非常高的功耗(DSP/SerDes 都是吃電怪獸)、交換延遲不穩定(buffer、queue、pipeline)、封包處理邏輯複雜、傳輸線路佈局難以變動。
而OCS做到的是:光纖 A 接到光纖 B,
光 → 光
中間完全不轉換成電訊號,不做封包。其中沒有DSP、沒有SerDes、也沒有電交換(ASIC)等晶片,因此功耗極低。因為沒有封包處理、沒有Buffer緩衝區、沒有ASIC線路分配,所以延遲極低且高度穩定。歸納而言,OCS能夠解決上述痛點的核心原理,在於其「專屬光路」的設計和「速率無關」的特性。在大規模AI訓練中,流量模式大多是穩定的、可預測的、且持續時間較長(例如:模型訓練期間的集體通訊)。OCS可以在流量路徑建立後,將光訊號直接導引至目的地,避免了在交換晶片中重複的O/E/O轉換。這直接消除了電交換的功耗和發熱問題,同時將延遲降到光速傳播的物理極限,顯著提升了AI集群的訓練效率。Google的實際部署結果證實,OCS能有效減輕Spine層的網路壓力
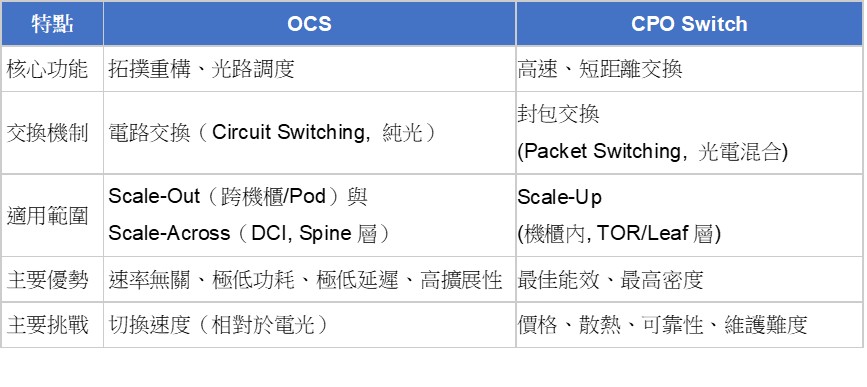
OCS and CPO Switch 的差異與關係
一談到光通訊的交換器(Switch),相信許多人會直接聯想到目前很紅的共同封裝光學(CPO) 交換器。OCS與CPO Switch是AI網路架構中兩種不同的光學革新方向,它們並非是互相取代的競爭者,而是在大型AI 資料中心互補的雙核心夥伴。CPO的目標是解決機櫃內部將光學元件移近交換器ASIC,從而最大程度地減少電訊號的訊息損耗和功耗問題,其主要負責高速、短距離的封包交換,適用於機櫃內的TOR(Top-of-Rack)或Leaf層。因此 CPO 的「戰場」位置非常明確,用於 Scale-Up 與 Scale-Out 接近交換 ASIC 的短距離高速互連。從許多測試資料顯示,CPO相較於可插拔模組可節能約65%。而OCS的「戰場」是目標解決大規模集群間的光路佈建重構與互連(Scale-Out與Scale-Across),簡單的說是把交換行為從光電轉換領域搬到光域,使整個網路架構變得更扁平、更省電、可動態重構。它負責Spine層和DCI(Data Center Interconnect)的低功耗、長距離、動態連接。整體來說,CPO優化了AI節點內部的交換(縮短電訊號的傳輸距離,效率最大化);OCS優化了AI節點之間的連接(拓撲彈性與功耗最佳化)。OCS 與CPO的比較表,如表二。
表二. OCS 與CPO的比較表
 September_AI Feature|Profitable Superstar of AI Era:Palantir
September_AI Feature|Profitable Superstar of AI Era:Palantir AI 光通訊專題|2026年OCS在AI資料中心發展趨勢研究(下)
AI 光通訊專題|2026年OCS在AI資料中心發展趨勢研究(下)





