
AI晶片專題|一個人的雲端之AI 訓練晶片趨勢解析(上)
Author: Mr. Lin Weizhi, Executive Vice President, Ji-Pu Industrial Trend Research Institute
Recently Daniel Kokotajlo and other authors published an AI development roadmap forecast report, AI 2027, which makes some bold situational projections for AI development in the coming years. Kokotajlo, a former researcher on OpenAI's Governance and Security team, predicted in 2021 that "Chain Thinking (CoT) will become a must-have capability for large-scale models, export controls on AI chips will be upgraded, and million-dollar training costs will be incurred by 2024." All of these predictions were later hit, and he was named by Time100 and Lawfare as one of the few people who managed to hit the AI roadmap in the long-term. He was also named by Time100 and Lawfare as "one of the few people who have managed to stay on the AI path for a long time. When he left OpenAI, he gave up millions of dollars in stock just to publicly warn about the ethical and governance risks of AI. This kind of dramatic reaction of not loving the real gold but loving the truth, together with the previous accurate AI development path prediction, also added a lot of anticipation and readability to the AI 2027 published by them this time. In the article, the match between two fictitious companies "OpenBrain (US) vs. DeepCent (China)" is used as the backbone to depict the path of explosive changes of AI agents from 2025 to 2027, and even the pessimistic ending mentions the possible extinction of human beings in 2030. The authors emphasize that the marginal effects of AI (the state of progress) will, in turn, accelerate the next round of AI research from the first generation of
- 算力層次差異,也就是LLM(大型語言模型) 訓練仍需雲端百萬顆 GPU;而低延遲推論、機器視覺等必須在邊緣或終端完成。
- 另一個是成本、功耗、佈署。2027年單顆雲端 GPU 逾 700 W,而可攜裝置 SOC/NPU 必須壓到 <10 W。
這兩個限制同時也告訴我們,「大模型+多層級硬體(邊緣與終端)」才是AI Agent真正能規模化的前提,雲端所訓練出來高品質的模型提供參數更新與高並行推論,邊緣負責即時的部分推論與大部分決策,終端裝置則把Agent帶到人身邊或生產線末端。因此AI Agent 並非單靠「巨大模型」即可達成,還必須將雲端、邊緣、終端的能力疊加起來。雲端仍是 LLM 訓練大本營,但低延遲推論、工廠視覺與個人助理等場景,需要把部分能力搬到邊緣/終端。隨著 Agent-3 開始「自動科研」,成本功耗成了瓶頸:單顆雲端 GPU 已達700W(功耗 瓦特) ,手持裝置 NPU 必須 <10W 才能普及。這解釋了為何 2024-2025 NVIDIA與OEM 搶推 “低功耗 GB200-Inference” 版本,也預示 2026 後Edge SoC 及模組競爭會異常激烈。無獨有偶,台積電在北美技術論壇的開場中,講者(資深副總 張曉強 博士)所提到:智慧無所不在(Intelligence Everywhere),人工智慧革命正在從資料中心往邊緣蔓延,且將融入每個設備以支援新的應用。
在AI Agent 來臨的時代,不只《AI 2027》的情境分析中看到,這次Computex 2025 NVIDIA黃仁勳的演講與訪談中也不斷地被提到。我們認為AI Agent 要大量普及,真正拐點並非模型單點突破,而會是在雲端+邊緣+終端三層算力(晶片)的同步成熟與商業閉環。目前三個應用場域的晶片比較如下表一。
表一. 雲端、邊緣、終端三大應用場域之晶片比較
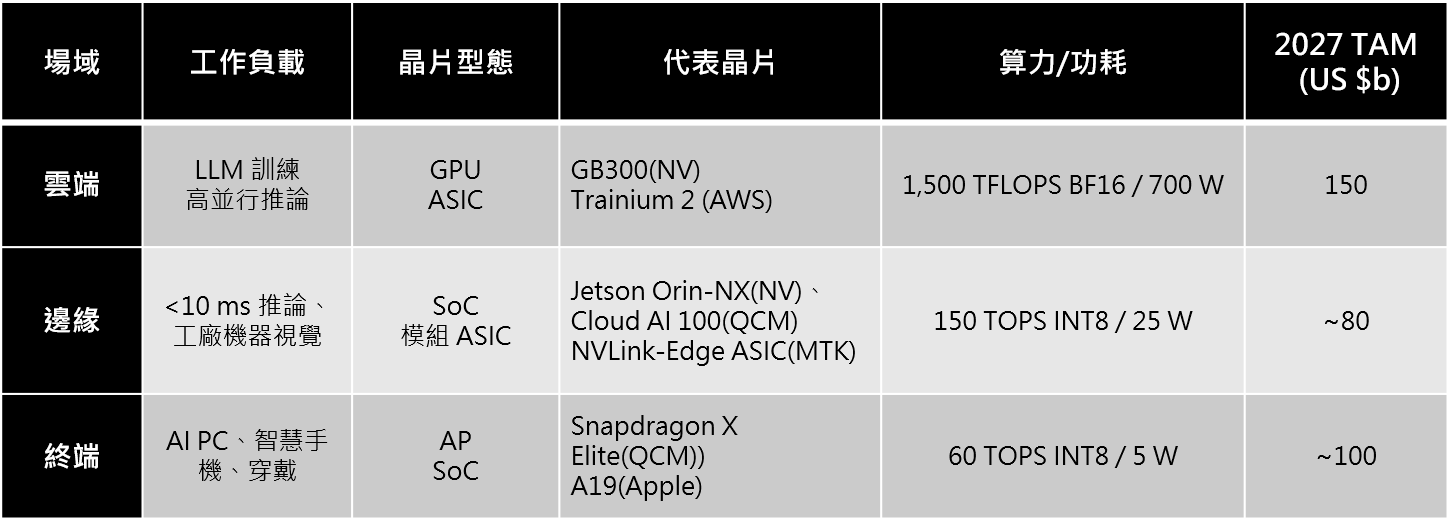
Source. IDC、TrendForce、《AI 2027》;智璞產業趨勢研究所整理
晶片未來的競爭重點如下:
- 雲端AI晶片戰場聚焦:先進封裝與HBM良率、光/矽光互連減瓶頸;指令集開放化、異質集群與能耗最適化;軟硬協同、供應鏈彈性與生態規模決定勝敗。加速器多元化、開源模型與雲運算成本三角平衡。
- 邊緣運算 SoC/ASIC 必須在維持既定算力的前提下,持續把 TOPS/W 極限向下推;整合高速網路(5G、Wi-Fi 7、乙太網)的傳輸效能,同時最佳化吞吐與延遲讓負載平衡更優化;內建加解密與運算配額機制,以兼顧隱私、防護與系統穩定性。
- 而終端的部分,應屬於作業平台與App迅速拉升裝置滲透率,NP的能力將成為裝置升級的催化劑。
本次專題討論將聚焦於訓練極限與低延遲推論這兩項我認為最具爆發性的戰線,也就是『雲端 × 邊緣』,以目前主流應用來看同樣可以視作『訓練 × 推論』的晶片討論。而終端(手機/AI PC/智慧穿戴等)晶片雖說也同樣重要,但目前仍屬換機驅動的創新,晶片架構特性與性能容易被其他變數影響,像是使用者友善的APP或外觀設計等,因此對AI Agent 生態的結構性衝擊相對有限,故暫列為後續專章討論。








