
AI模型專題|大語言模型的運作、極限與突破(下)
Author: Mr. Lin Weizhi, Executive Vice President, Ji-Pu Industrial Trend Research Institute
OpenAI's O-series models, DeepSeek R1/R1 zero, and xAI's recently launched Grok 3 are all equipped with reasoning capabilities, but according to KOLs and related papers on the Internet, we can still speculate on their core technologies and design concepts:
- Adding Reinforcement Learning to the original Pretraining process in LLM.
- In the final Inference Model (Inference Model) also added Reinforcement Learning (Reinforcement Learning) and Monte Carlo Tree Search (MCTS), etc., mainly to enhance or improve the test computing resources (Test-Time Compute).
In terms of end-inference users, the core mechanism of O3 is modeled in the
另外一個模型可以擴展(Scaling)的原因為測試計算資源(Test-Time Compute)的進步。過去模型擴展的策略主要集中在增大參數量(如 GPT-3、GPT-4的參數持續增加),但後來發現這不但會導致「成本過度膨脹」,且「在固定的計算資源下,若給出更大的參數,也會導致模型推論鈍化」。有新的研究(如O1)認為在固定的預算下,若適當增加測試計算資源(Test-Time Compute),如蒙特卡洛樹搜尋(MCTS)或動態計算,可能會比單純增加模型參數更加有效,且讓大語言模型(LLM)在回答問題時更加靈活、準確。如圖三,AlphaGo Zero未加入Test-Time Compute前的表現較差(灰色長條圖),但在加入MCTS後的表現得到大幅的成長(藍色長條圖)。
圖三、AlphaGo Zero在適當增加測試計算資源後的表現
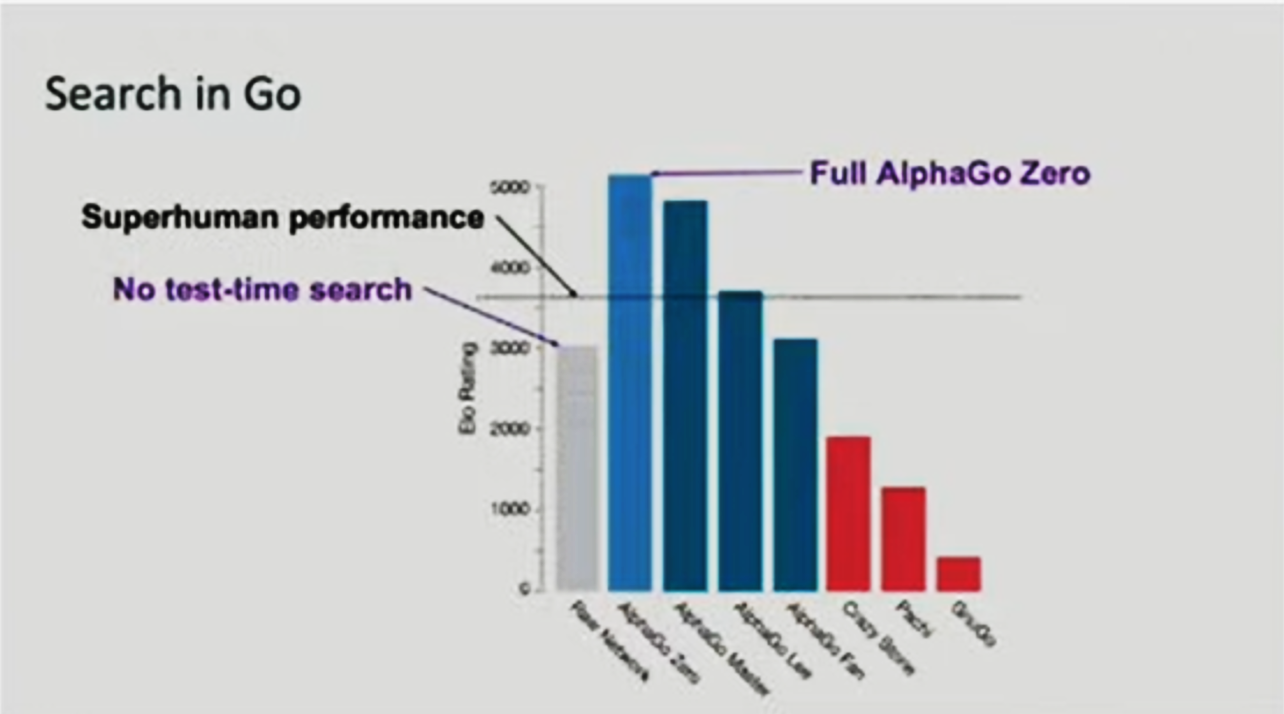
資料來源:KIMI
AGI並非侷限於某個特定領域,而是可以靈活應用於任何場景,若可以在模型中引入RL使其具備自主訓練及推理能力(Reasoning),就能更接近AGI。不過目前的計算成本高昂,傳聞O3(高算力版)在計算一題Arc-AGI題目時,成本高達3400美元,也因此突顯出了測試計算資源(Test-Time Compute)之重要性。從目前論文來看,強化學習(RL)具備可擴展性(Scaling),不只可以運用在訓練模型,也可以優化推理過程。
之所以AI 發展不會放緩,正是因為 AGI(通用人工智慧) 尚未實現,而當前的研究主要聚焦於三大方向:
- 大語言模型(LLM)——透過文本與語言理解世界,其學習方式依賴Token-by-Token 的統計數據來建立語意關聯。
- 強化學習(RL)——讓AI主動探索環境,自主學習物理世界的規律,而非僅依賴已有數據。
- 自監督學習(JEPA, Joint Embedding Predictive Architecture)——這一概念尚未有具體模型落地,但被視為可能的未來發展路徑。
目前AGI 的實現仍仰賴更強大的計算資源,而RL的擴展(Scaling)才剛剛開始。這也意味著訓練專用的 GPU、NPU、TPU 等 AI 晶片需求將持續攀升,為產業發展帶來更大的技術挑戰與機遇。
從ChatGPT O1到O3的推出只相差短短三個月,其中推理能力卻已有顯著提升,這不僅展現出測試計算資源(Test-Time Compute)、蒙特卡洛樹搜尋(MCTS)等技術方法的持續擴展(Scaling),也帶動更多客製化AI服務的出現。順著此趨勢發展下,將迎來更高的OPEX(營運支出)及針對ASIC、模型與AI晶片的強化需求,加速推動整體生態系的升級。然而,科研仍在持續演進,技術仍在持續突破。根據相關論文研究(如圖四),具有較強結構約束的學習方法(如MCTS、監督式學習等)雖能穩定提升模型表現,但最終將會趨於飽和,且較無法向上突破。而結構較少的學習方式雖然在初期的表現受限,但在計算資源足夠時,將展現出更顯著的性能提升。科技發展日新月異,結構化的資料型態未必是AI模型強化的唯一解方,未來的發展方向或許將依賴更靈活、多元的學習架構,以實現真正的智能進化。
圖四、不同結構學習方法與性能表現的影響
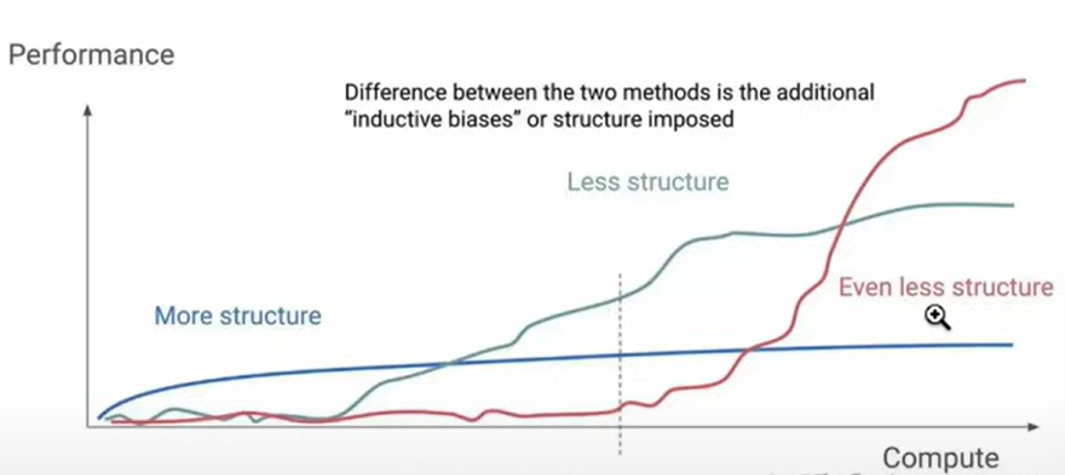
資料來源:KIMI








